目的
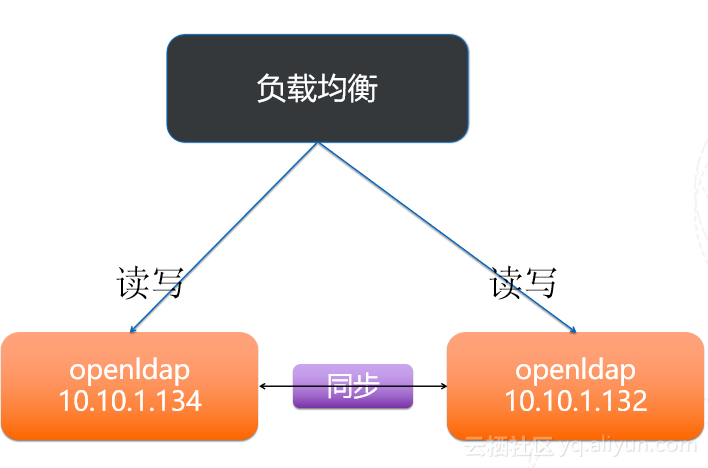
在实际产线运维环境下,使用最多的就是镜像模式,当然多IDC机房的情况下也会结合使用其他模式,例如主从模式。
镜像模式只允许2个主节点,如果超过2个节点其他节点只会同步获取前面2个节点的配置(这个是博客文档里面看到的,没有验证)
环境
| 主机名称 | 地址 | 版本 | 角色 | 备注 |
|---|---|---|---|---|
| sysldap-shylf-1 | 10.116.72.11 | CentOS7.6 min | openLdap, httpd, phpldapadmin | 主节点 |
| sysldap-shylf-2 | 10.116.72.12 | CentOS7.6 min | openLdap, httpd, phpldapadmin | 主节点 |
| systerm-shylf-1 | 10.116.72.15 | CentOS7.6 min | openLdap client |
前提条件,为了方便配置防火墙以及禁用selinux
配置示例:dc=example,dc=com