Socket Server模块
SocketServer内部使用 IO多路复用 以及 “多线程” 和 “多进程” ,从而实现并发处理多个客户端请求的Socket服务端。即:每个客户端请求连接到服务器时,Socket服务端都会在服务器是创建一个“线程”或者“进程” 专门负责处理当前客户端的所有请求。
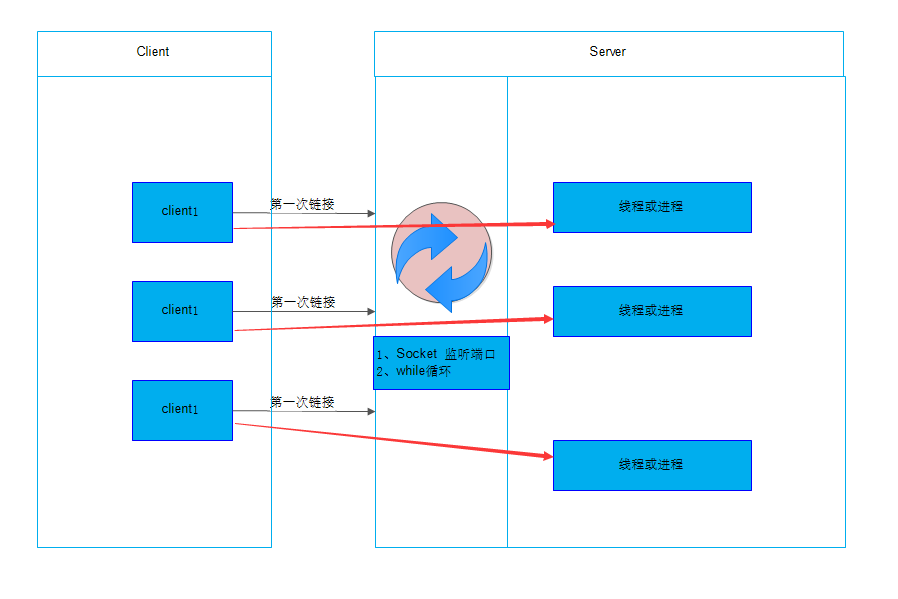
socket server和select & epoll 还是不太一样他的本质是:客户端第一次链接的时候,只要一进来,我服务端有个while循环为你创建一个
线程和进程,客户端就和服务端直接创建通信,以后传送数据什么的就不会通过server端了,直接他俩通过线程或者进程通信就可以了!
如果在多进程的时候,client1和client2他们同时传输10G的文件都是互相不影响!
如果在多线程的时候,python中的多线程,在同一时间只有一个线程在工作,他底层会自动进行上下文切换,client1传一点,client2传一点。
知识回顾:
python中的多线程,有一个GIL在同一时间只有一个线程在工作,他底层会自动进行上下文切换.
这样会导致python的多线程效率会很低,也就是人们经常说的python多线程问题
如下图:
第一次连接后,数据通讯就通过线程或进程进行数据交换(红色箭头)
ThreadingTCPServer
ThreadingTCPServer实现的Socket服务器内部会为每个client创建一个 “线程”,该线程用来和客户端进行交互。
ThreadingTCPServer基础
使用ThreadingTCPServer:
- 创建一个继承自 SocketServer.BaseRequestHandler 的类
- 类中必须定义一个名称为 handle 的方法
- 启动ThreadingTCPServer
1 | #!/usr/bin/env python |
1 | #!/usr/bin/env python |
ThreadingTCPServer源码剖析
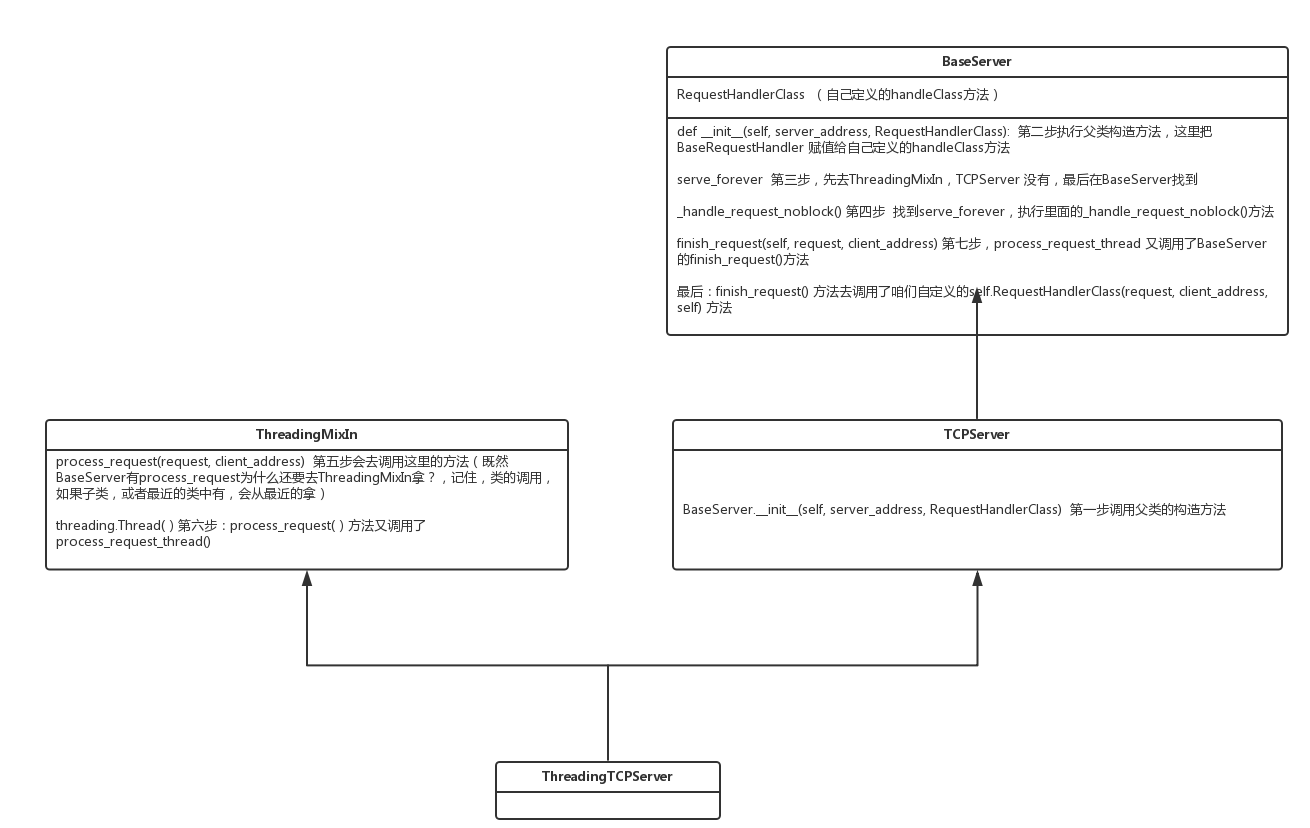
学会看源码非常重要!不能仅仅光会用!大赞~ 知道他的过程和实现~ 怎么学会看源码呢?多看然后画类图,如上图!!!
在理解的时候可以把他们想象为,把所有需要用的方法,都抓到ThreadingTCPServer中
内部调用流程为:
- 启动服务端程序
- 执行 TCPServer.init 方法,创建服务端Socket对象并绑定 IP 和 端口
- 执行 BaseServer.init 方法,将自定义的继承自SocketServer.BaseRequestHandler 的类 MyRequestHandle赋值给 self.RequestHandlerClass
- 执行 BaseServer.server_forever 方法,While 循环一直监听是否有客户端请求到达 …
- 当客户端连接到达服务器
- 执行 ThreadingMixIn.process_request 方法,创建一个 “线程” 用来处理请求
- 执行 ThreadingMixIn.process_request_thread 方法
- 执行 BaseServer.finish_request 方法,执行 self.RequestHandlerClass() 即:执行 自定义 MyRequestHandler 的构造方法(自动调用基类BaseRequestHandler的构造方法,在该构造方法中又会调用 MyRequestHandler的handle方法)
精简源码:
模拟Socekt Server的简化版本:
1 | import socket |
如精简代码可以看出,SocketServer的ThreadingTCPServer之所以可以同时处理请求得益于 select 和 Threading 两个东西,其实本质上就是在服务器端为每一个客户端创建一个线程,当前线程用来处理对应客户端的请求,所以,可以支持同时n个客户端链接(长连接)。
ForkingTCPServer
ForkingTCPServer和ThreadingTCPServer的使用和执行流程基本一致,只不过在内部分别为请求者建立 “线程” 和 “进程”。
1 | #!/usr/bin/env python |
1 | #!/usr/bin/env python |
以上ForkingTCPServer只是将 ThreadingTCPServer 实例中的代码:
1 | server = SocketServer.ThreadingTCPServer(('127.0.0.1',8009),MyRequestHandler) |
Python线程
Threading用于提供线程相关的操作,线程是应用程序中工作的最小单元。
1 | #!/usr/bin/env python |
上述代码创建了10个“前台”线程,然后控制器就交给了CPU,CPU根据指定算法进行调度,分片执行指令。
再次回顾:这里为什么是分片执行?
python中的多线程,有一个GIL(Global Interpreter Lock 全局解释器锁 )在同一时间只有一个线程在工作,他底层会自动进行上下文切换.这个线程执行点,那个线程执行点!
更多方法:
- start 线程准备就绪,等待CPU调度
- setName 为线程设置名称
- getName 获取线程名称
- setDaemon 设置为后台线程或前台线程(默认)
- 如果是后台线程,主线程执行过程中,后台线程也在进行,主线程执行完毕后,后台线程不论成功与否,均停止
- 如果是前台线程,主线程执行过程中,前台线程也在进行,主线程执行完毕后,等待前台线程也执行完成后,程序停止
- join 逐个执行每个线程,执行完毕后继续往下执行,该方法使得多线程变得无意义
- run 线程被cpu调度后执行Thread类对象的run方法
线程锁
由于线程之间是进行随机调度,并且每个线程可能只执行n条执行之后,CPU接着执行其他线程。所以,可能出现如下问题:
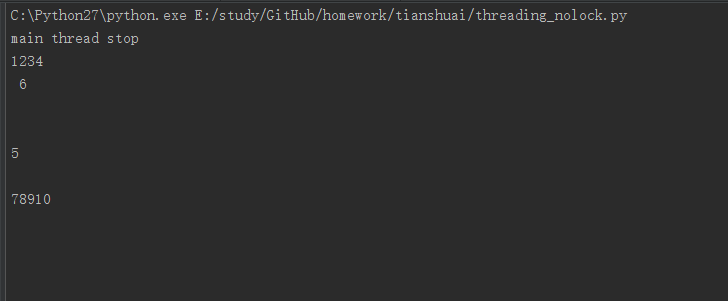
1 | #!/usr/bin/env python |
设置线程锁
1 | #!/usr/bin/env python |
event
他的作用就是:用主线程控制子线程合适执行,他可以让子线程停下来,也可以让线程继续!
他实现的机制就是:标志位“Flag”
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。
- clear:将“Flag”设置为False
- set:将“Flag”设置为True
1 | #!/usr/bin/env python |
Python进程
1 | from multiprocessing import Process |
注意:由于进程之间的数据需要各自持有一份,所以创建进程需要的非常大的开销。并且python不能再Windows下创建进程!
并且在使用多进程的时候,最好是创建多少个进程?:和CPU核数相等
默认的进程之间相互是独立,如果想让进程之间数据共享,就得有个特殊的数据结构,这个数据结构就可以理解为他有穿墙的功能
如果你能穿墙的话两边就都可以使用了
使用了3种方法
默认的进程无法进行数据共享:
1 | #!/usr/bin/env python |
使用特殊的数据类型,来进行穿墙:
1 | 默认的进程之间相互是独立,如果想让进程之间数据共享,就得有个特殊的数据结构,这个数据结构就可以理解为他有穿墙的功能 |
OK那么问题来了,既然进程之间可以进行共享数据,如果多个进程同时修改这个数据是不是就会造成脏数据?是不是就得需要锁!
进程的锁和线程的锁使用方式是非常一样的知识他们是用的类是在不同地方的
1 | #!/usr/bin/env python |
进程池
进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply
- apply_async
1 | #!/usr/bin/env python |
协程
首先要明确,线程和进程都是系统帮咱们开辟的,不管是thread还是process他内部都是调用的系统的API
而对于协程来说它和系统毫无关系!
他就和程序员有关系,对于线程和进程来说,调度是由CPU来决定调度的!
对于协程来说,程序员就是上帝,你想让谁执行到哪里他就执行到哪里
协程存在的意义:对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。
适用场景:其实在其他语言中,协程的其实是意义不大的多线程即可已解决I/O的问题,但是在python因为他有GIL(Global Interpreter Lock 全局解释器锁 )在同一时间只有一个线程在工作,所以:如果一个线程里面I/O操作特别多,协程就比较适用
greenlet
1 | 收先要明确,线程和进程都是系统帮咱们开辟的,不管是thread还是process他内部都是调用的系统的API |
协程就是对线程的分片,上面的例子需要手动操作可能用处不是很大了解原理,看下面的例子:
上面的greenlet是需要认为的制定调度顺序的,所以又出了一个gevent他是对greenlet功能进行封装
遇到I/O自动切换
1 | from gevent import monkey; monkey.patch_all() |

