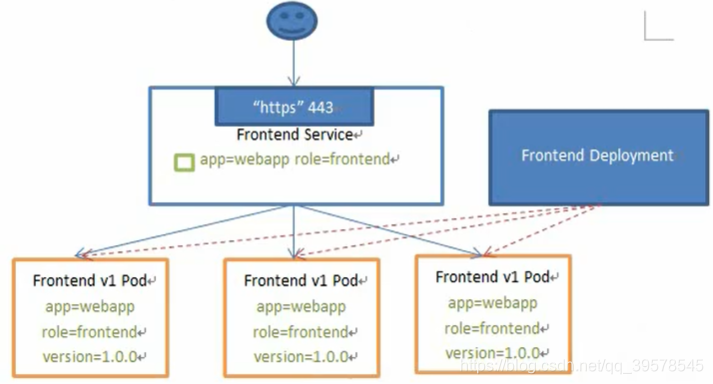
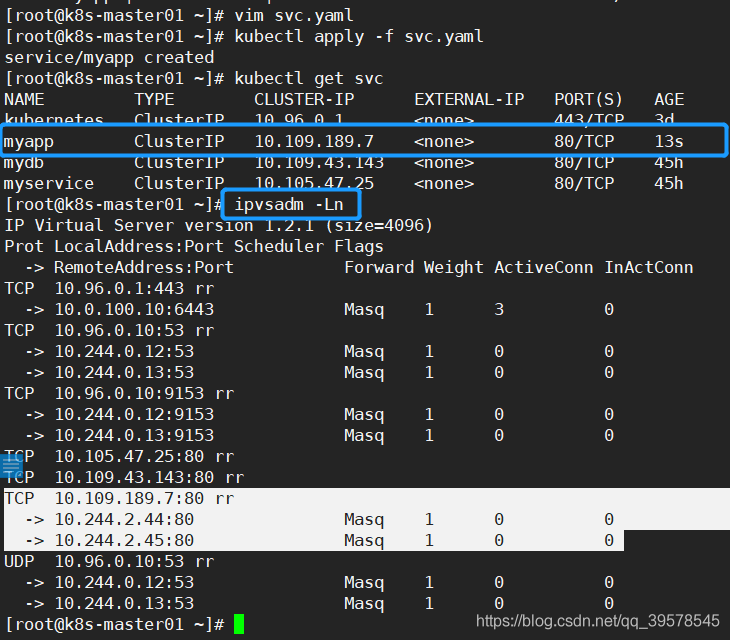
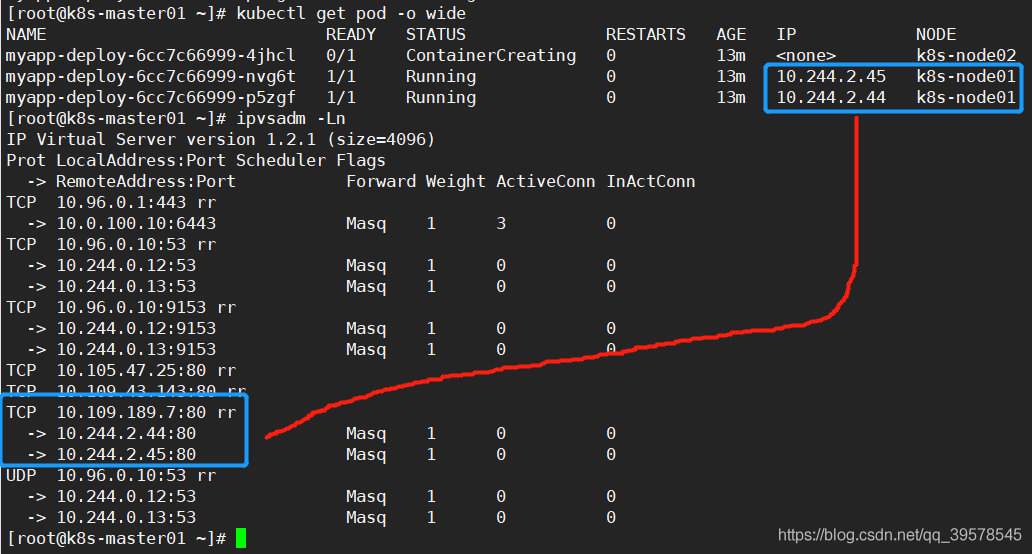
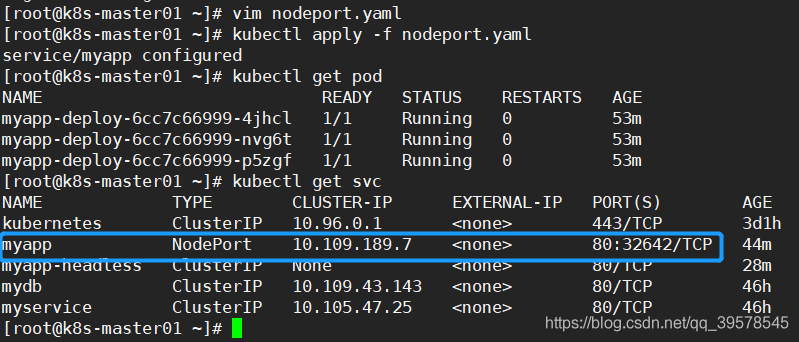
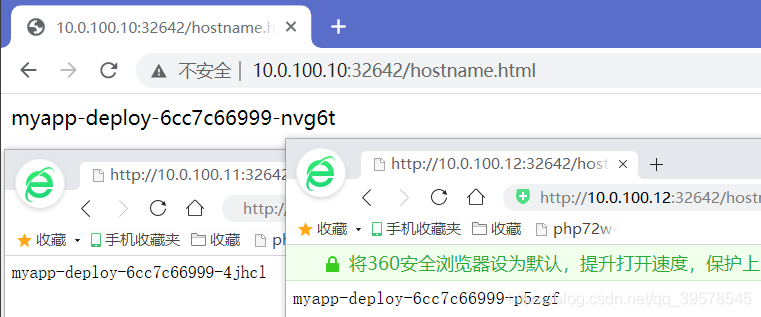
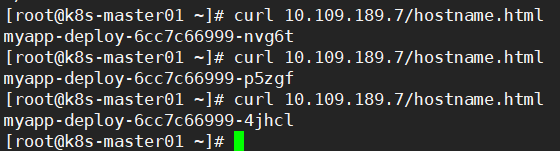
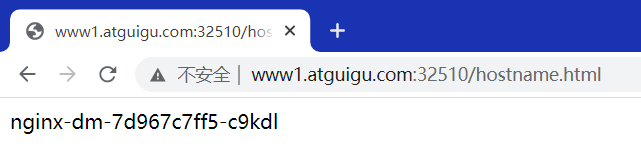
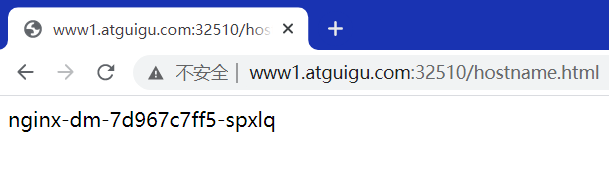
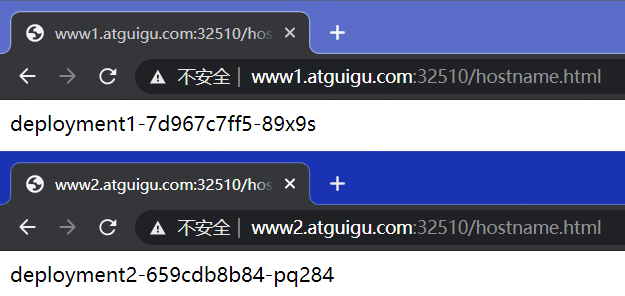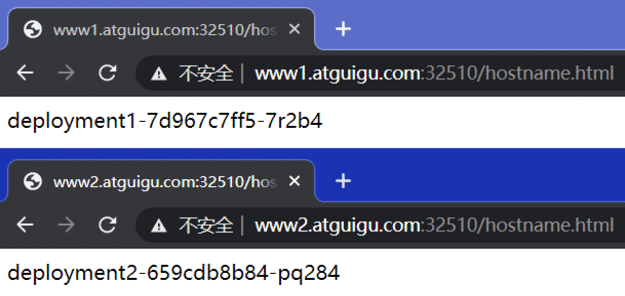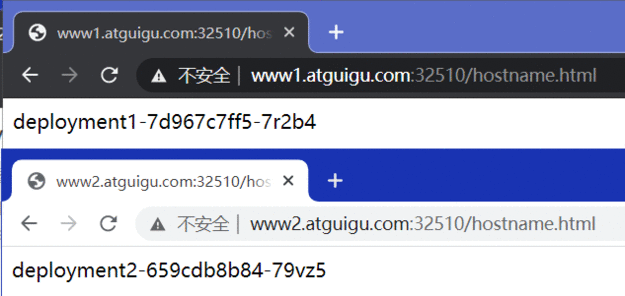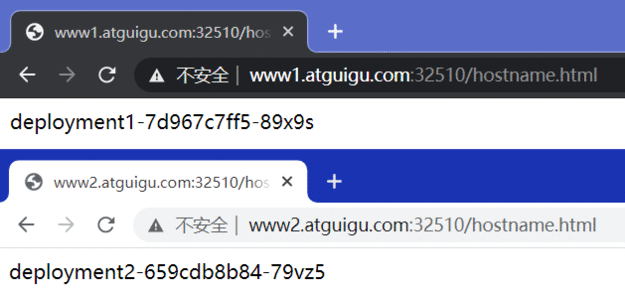
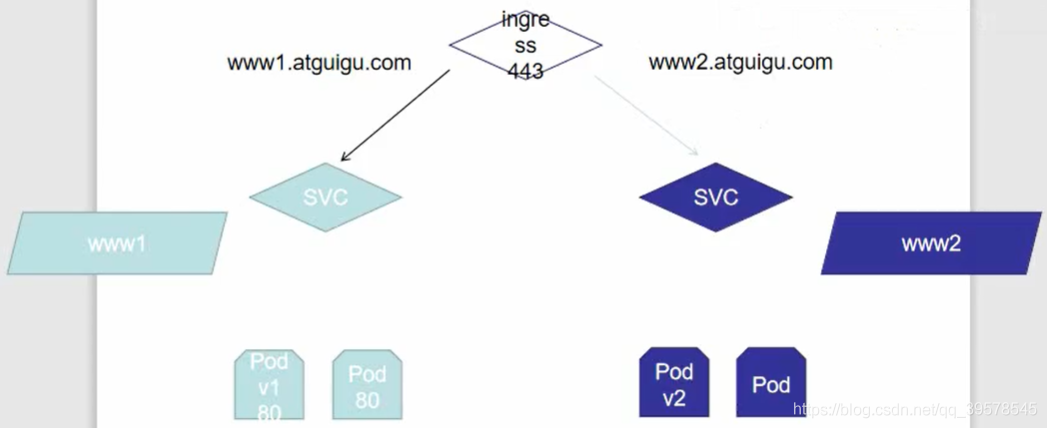
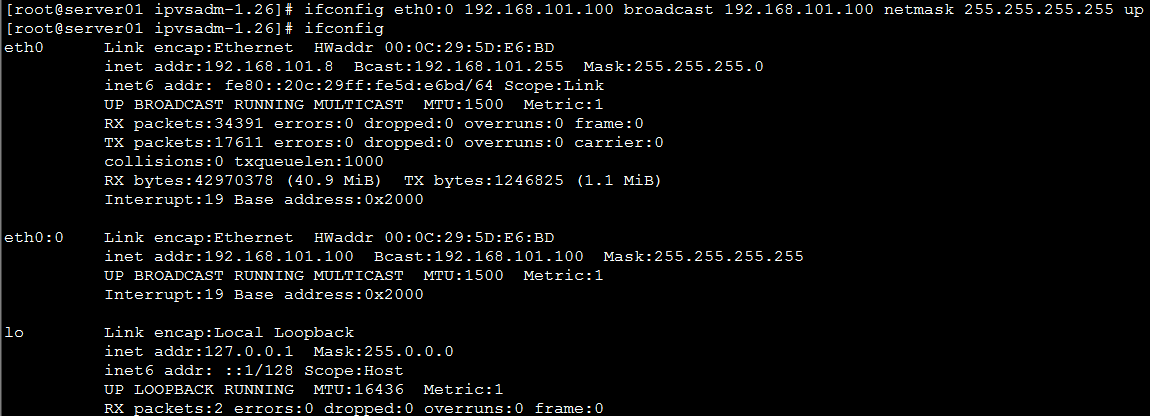
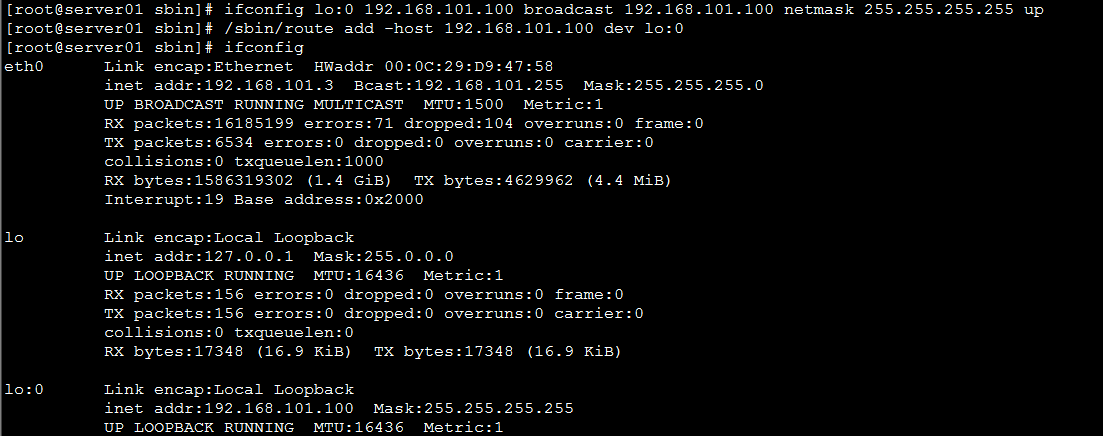
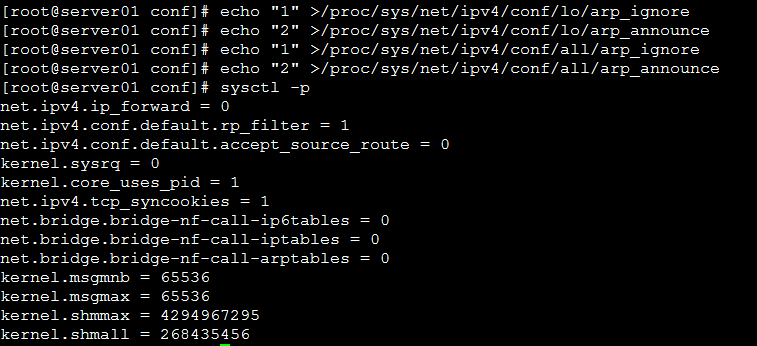
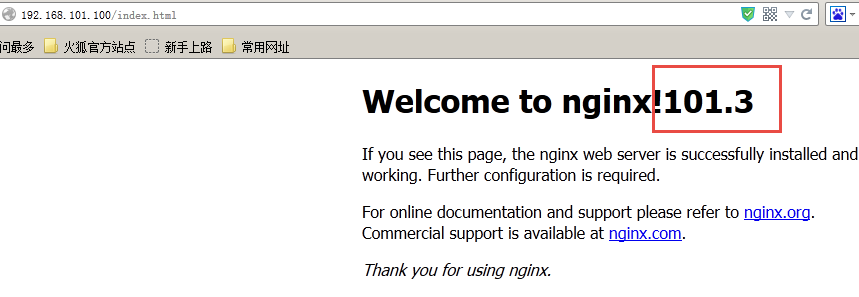
kubectl apply -f svc.yaml kubectl get svc ipvsadm -Ln
这里是两个的原因是因为有一个容器还在创建,没关系
kubectl delete -f svc.yaml 也可以看得到对应的服务也被删除了。
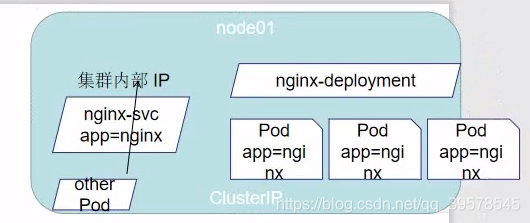
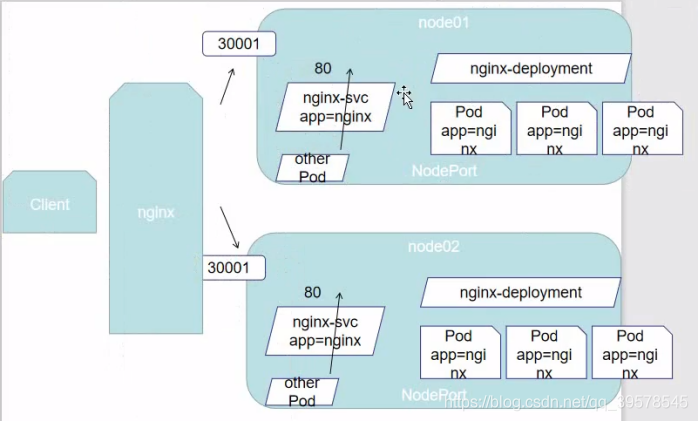
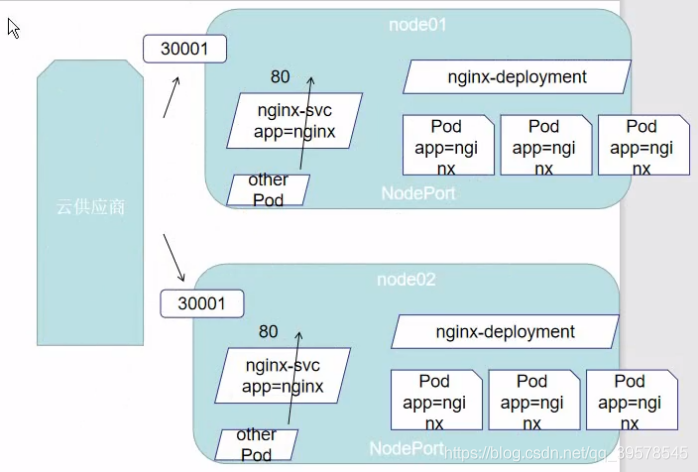
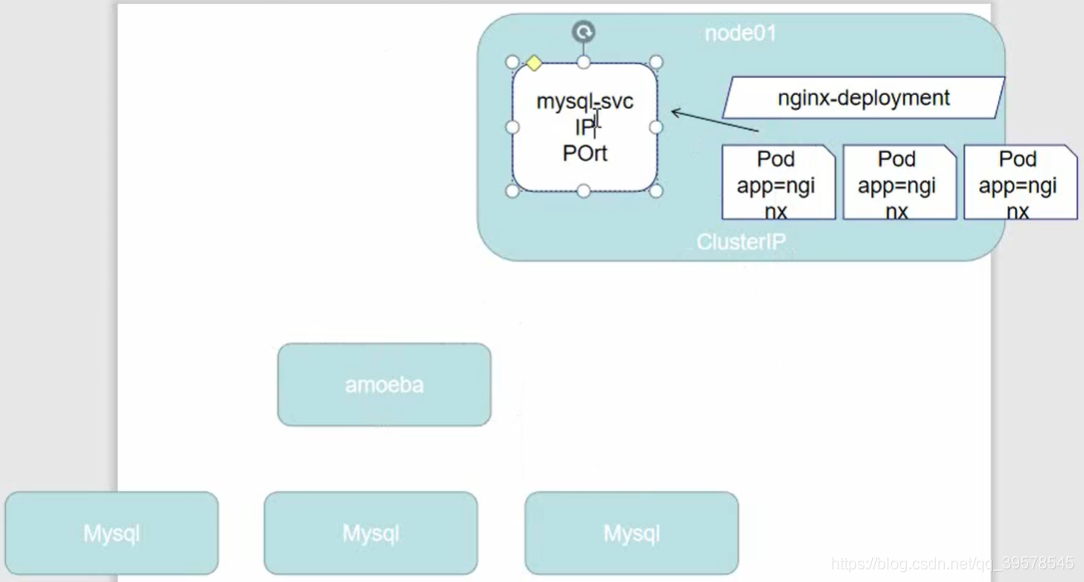
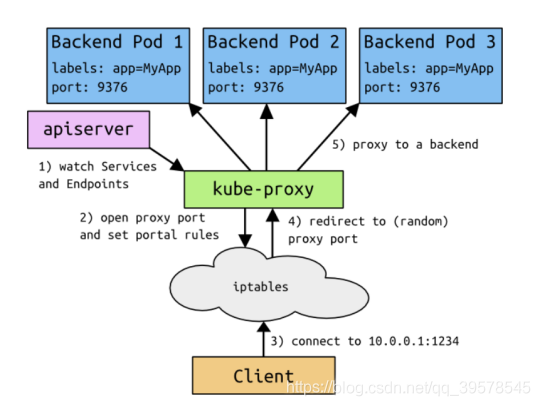
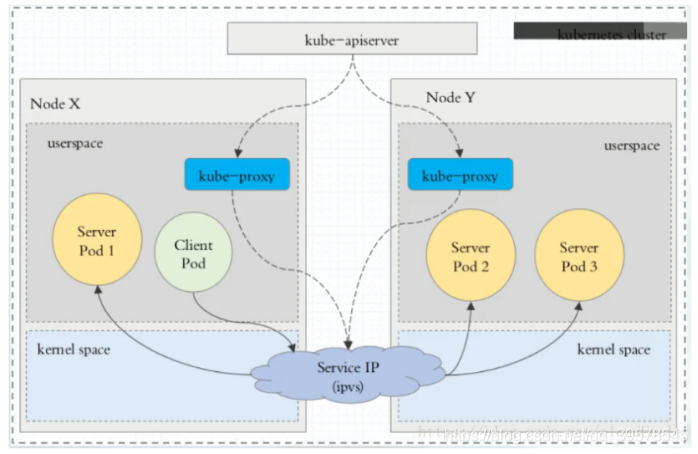
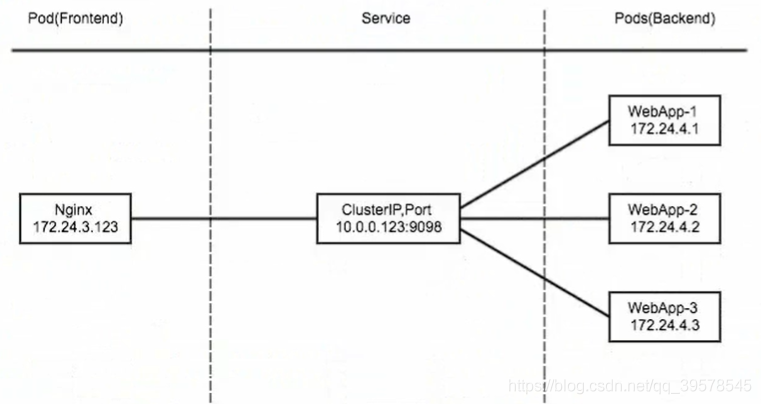
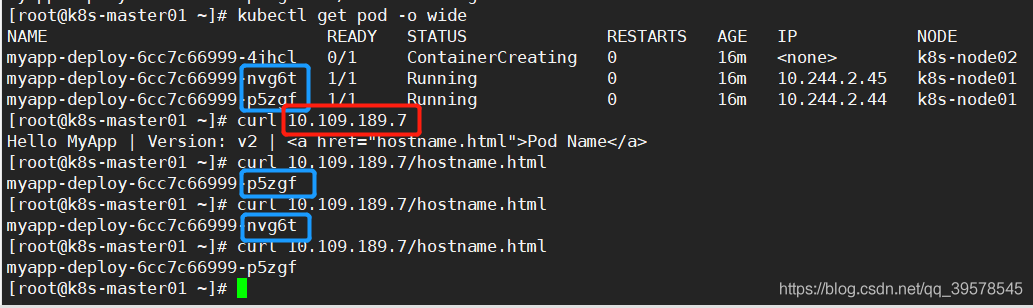
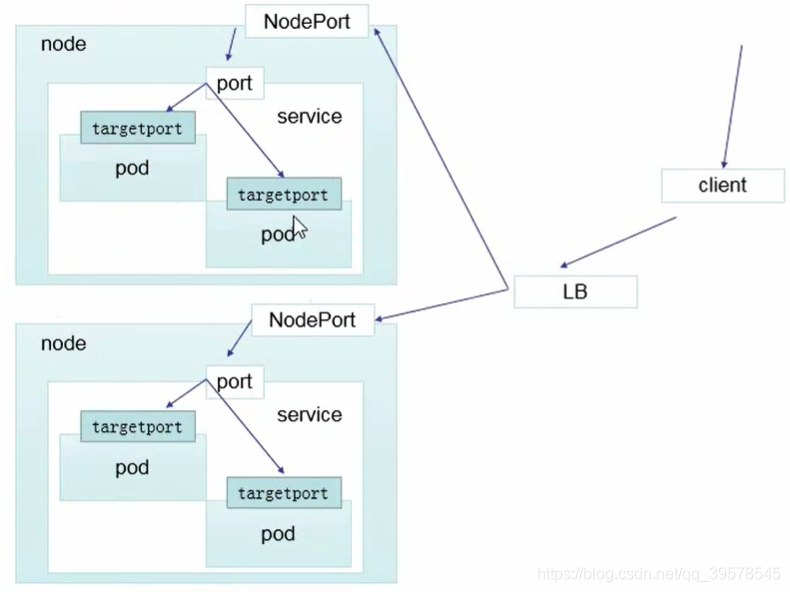
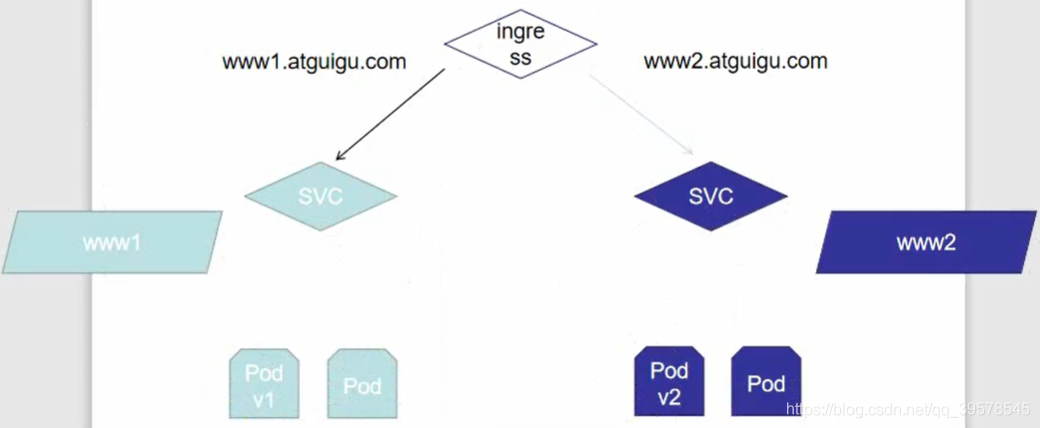
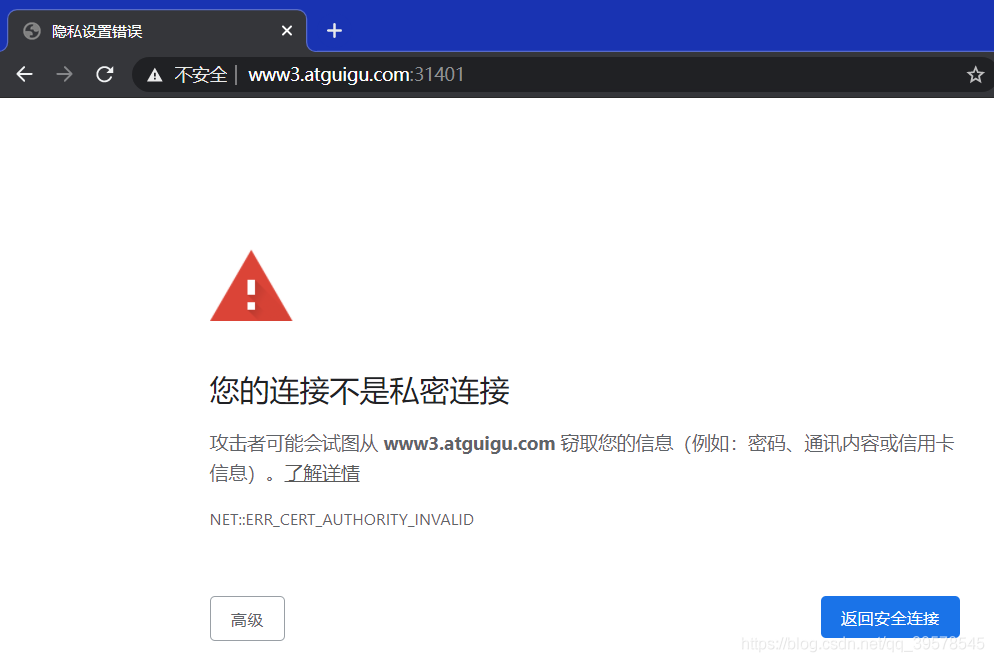
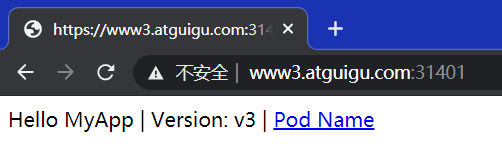
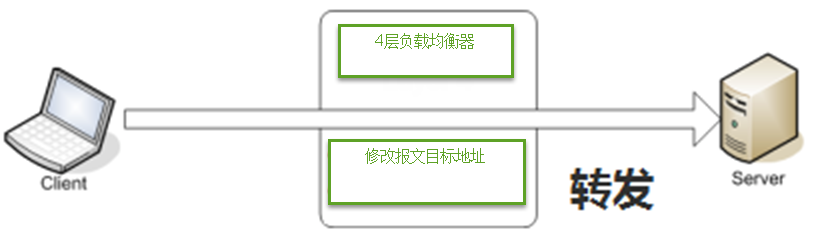
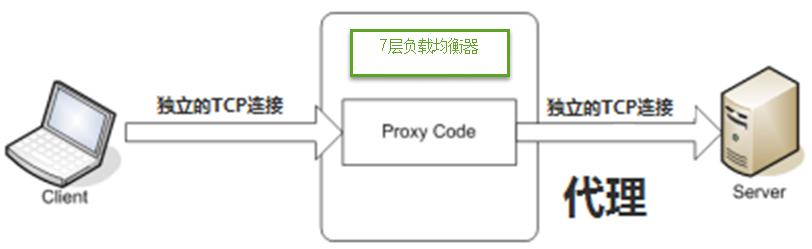
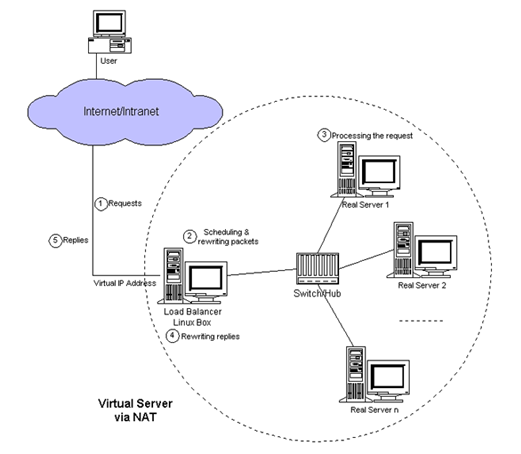
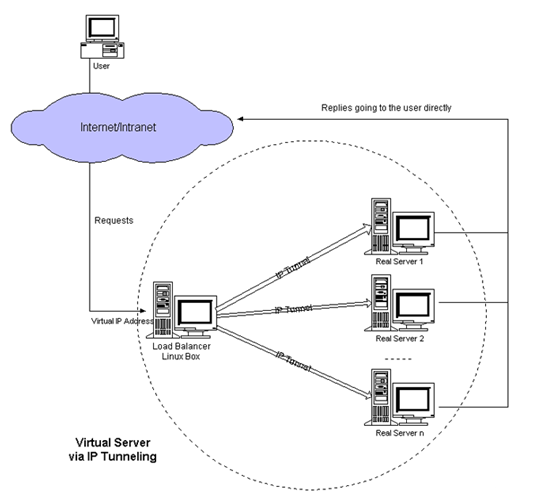
直接访问svc的IP地址,相当于通过ipvs模块,负载均衡,实现代理到后端节点上。
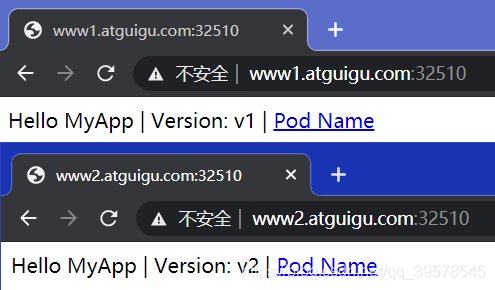
直接访问svc的IP地址,可以看到轮询RR效果
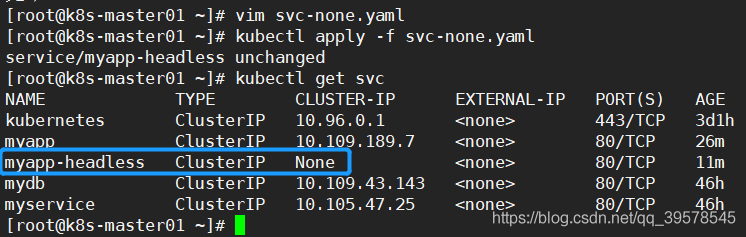
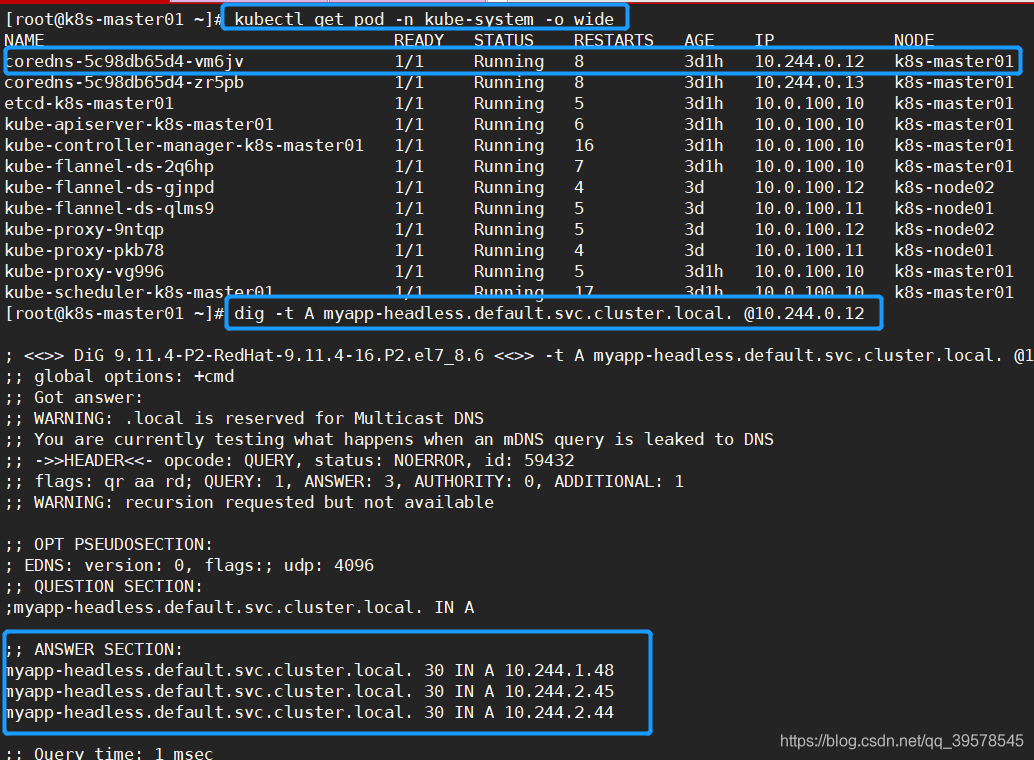
Headless Service
它属于一种特殊的Cluster IP, 有时不需要或不想要负载均衡,以及单独的 Service IP 。遇到这种情况,可以通过指定 ClusterIP(spec.clusterIP) 的值为 “None” 来创建 Headless Service 。这类 Service 并不会分配 Cluster IP, kube-proxy 不会处理它们,而且平台也不会为它们进行负载均衡和路由
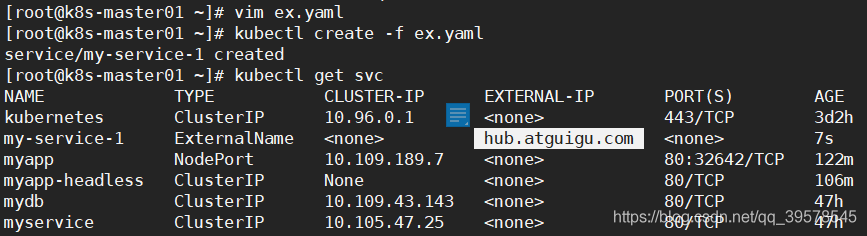
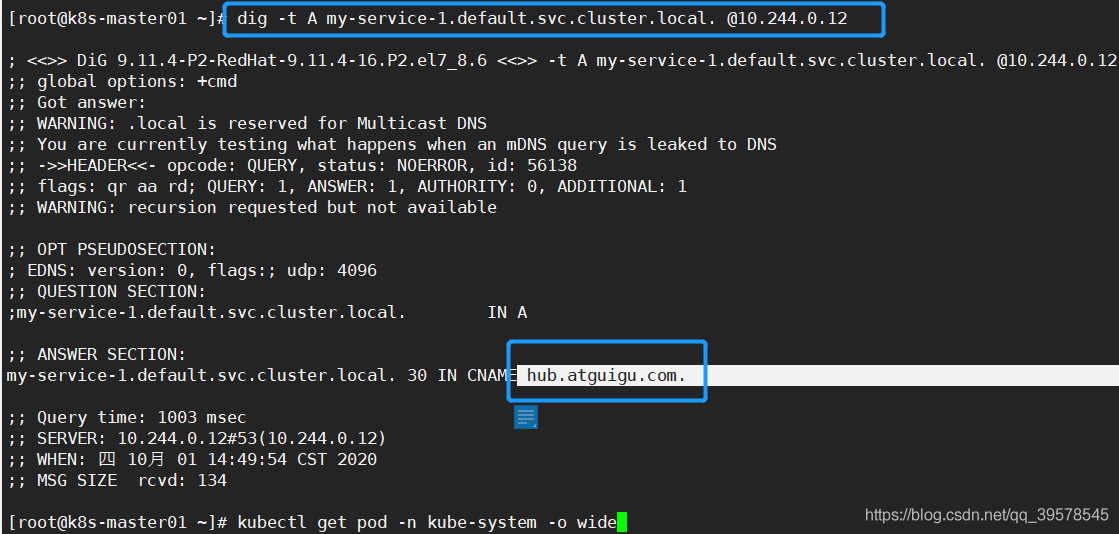
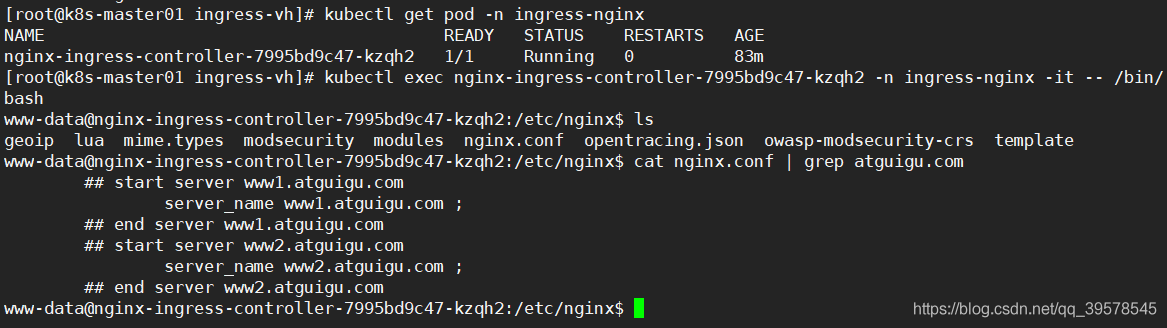
别名操作,外部服务引入到集群内 这种类型的 Service 通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容( 例如:hub.atguigu.com )。ExternalName Service 是 Service 的特例,它没有 selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务
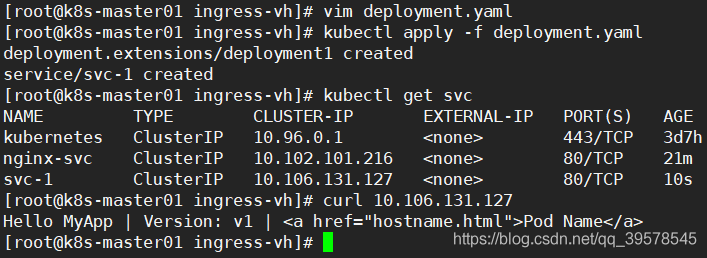
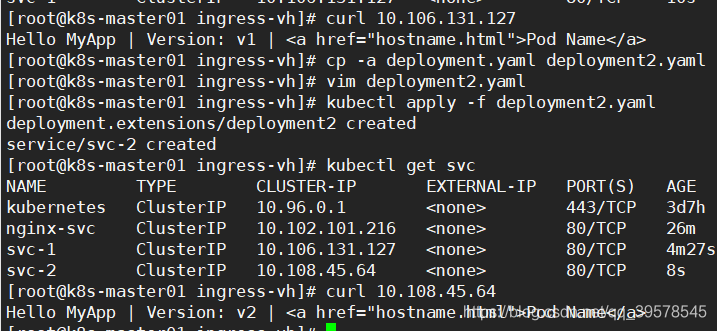
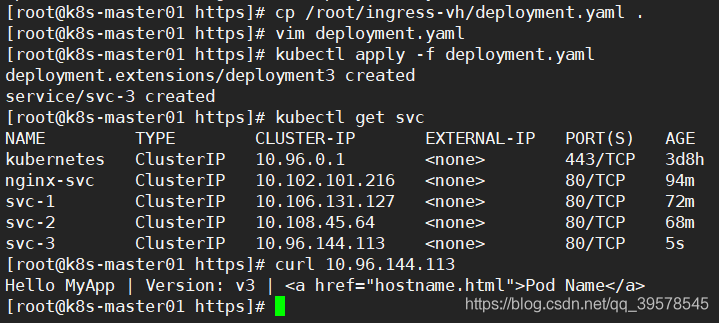
[root@k8s-master01 https]# kubectl apply -f deployment.yaml deployment.extensions/deployment3 created service/svc-3 created [root@k8s-master01 https]# kubectl get svc
; the below section must remain in the config file for RPC ; (supervisorctl/web interface) to work, additional interfaces may be ; added by defining them in separate rpcinterface: sections [rpcinterface:supervisor] supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl] serverurl=unix:///var/run/supervisor.sock ; use a unix:// URL for a unix socket 通过 UNIX socket 连接 supervisord,路径与 unix_http_server 部分的 file 一致
[root@titan ~]# id apple uid=1001(apple) gid=1001(fruit) 组=1001(fruit),10(wheel) [root@titan ~]# id banana uid=1002(banana) gid=1001(fruit) 组=1001(fruit)
验证apple
1 2
[apple@titan ~]$ su - root [root@titan ~]#
验证banana
1 2 3
[banana@titan ~]$ su - root su: 拒绝权限 [banana@titan ~]$
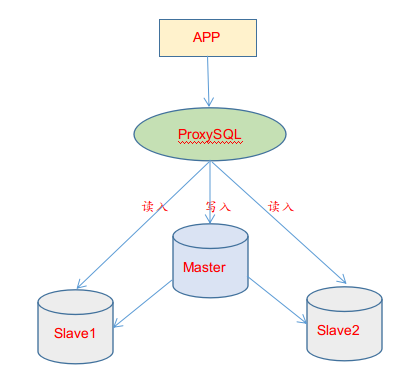
先在proxysql本机登录 (因为初始账号密码是admin:admin,只能在本机登录), 这里的proxysql本机地址是172.16.60.214 修改远程连接proxysql管理端口的账号和密码radmin:radmin. [root@mysql-proxy ~]# mysql -uadmin -padmin -h127.0.0.1 -P6032 Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 34 Server version: 5.5.30 (ProxySQL Admin Module) Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h'forhelp. Type '\c' to clear the current input statement. MySQL [(none)]> update global_variables set variable_value = 'admin:admin;radmin:radmin'where variable_name = 'admin-admin_credentials'; Query OK, 1 row affected (0.002 sec) MySQL [(none)]> LOAD ADMIN VARIABLES TO RUNTIME; Query OK, 0 rows affected (0.000 sec) MySQL [(none)]> SAVE ADMIN VARIABLES TO DISK; Query OK, 31 rows affected (0.077 sec) 这样就可以使用下面的命令在其他机器上使用radmin用户登录(其他机器上需要有mysql client) [root@MGR-node3 ~]# mysql -uradmin -pradmin -h172.16.60.214 -P6032 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 35 Server version: 5.5.30 (ProxySQL Admin Module) Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h'forhelp. Type '\c' to clear the current input statement. mysql> show databases; +-----+---------------+-------------------------------------+ | seq | name | file | +-----+---------------+-------------------------------------+ | 0 | main | | | 2 | disk | /var/lib/proxysql/proxysql.db | | 3 | stats | | | 4 | monitor | | | 5 | stats_history | /var/lib/proxysql/proxysql_stats.db | +-----+---------------+-------------------------------------+ 5 rows inset (0.00 sec)
1) 添加配置 需要添加配置时,直接操作的是MEMORAY,例如:添加一个程序用户,在mysql_users表中执行一个插入操作: MySQL [(none)]> insert into mysql_users(username,password,active,default_hostgroup,transaction_persistent) values('myadmin','mypass',1,0,1); 这样就完成了一个用户的添加。要让这个insert生效,还需要执行如下操作: MySQL [(none)]>load mysql users to runtime; 表示将修改后的配置(MEMORY层)用到实际生产环境(RUNTIME层) 如果想保存这个设置永久生效,还需要执行如下操作: MySQL [(none)]>save mysql users to disk; 表示将memoery中的配置保存到磁盘中去。 除了上面两个操作,还可以执行如下操作: MySQL [(none)]>load mysql users to memory; 表示将磁盘中持久化的配置拉一份到memory中来。 MySQL [(none)]>load mysql users from config; 表示将配置文件中的配置加载到memeory中。 2) 持久化配置 以上SQL命令是对mysql_users进行的操作,同理,还可以对mysql_servers表、mysql_query_rules表、global_variables表等执行类似的操作。 如对mysql_servers表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令: MySQL [(none)]> load mysql servers to runtime; MySQL [(none)]> save mysql servers to disk; 对mysql_query_rules表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令: MySQL [(none)]> load mysql query rules to runtime; MySQL [(none)]> save mysql query rules to disk; 对global_variables表插入完成数据后,要执行保存和加载操作,可执行如下SQL命令: 以下命令加载或保存mysql variables(global_variables): MySQL [(none)]>load mysql variables to runtime; MySQL [(none)]>save mysql variables to disk; 以下命令加载或保存admin variables(select * from global_variables where variable_name like 'admin-%'): MySQL [(none)]> load admin variables to runtime; MySQL [(none)]>save admin variables to disk;
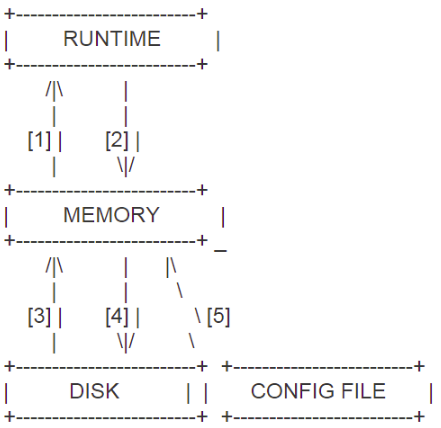
这三个级别的配置文件互不干扰,在某个层级修改了配置文件,想要加载或保存到另一个层级,需要额外的LOAD或SAVE操作:”LOAD xx_config FROM xx_level | LOAD xx_config TO xx_level | SAVE xx_config TO xx_level | SAVE xx_config FROM xx_level”,达到加载配置或者持久化配置的目的。这三层中每层的功能与含义如下: - RUNTIME层 代表的是ProxySQL当前生效的配置,包括 global_variables, mysql_servers, mysql_users, mysql_query_rules。无法直接修改这里的配置,必须要从下一层load进来。该层级的配置时在proxysql管理库(sqlite)的main库中以runtime_开头的表,这些表的数据库无法直接修改,只能从其他层级加载;该层代表的是ProxySQL当前生效的正在使用的配置,包括global_variables, mysql_servers, mysql_users, mysql_query_rules表。无法直接修改这里的配置,必须要从下一层load进来。也就是说RUNTIME这个顶级层,是proxysql运行过程中实际使用的那一份配置,这一份配置会直接影响到生产环境的,所以要将配置加载进RUNTIME层时需要三思而行。
- MEMORY层 是平时在mysql命令行修改的 main 里头配置,可以认为是SQLite数据库在内存的镜像。该层级的配置在main库中以mysql_开头的表以及global_variables表,这些表的数据可以直接修改;用户可以通过MySQL客户端连接到此接口(admin接口),然后可以在mysql命令行查询不同的表和数据库,并修改各种配置,可以认为是SQLite数据库在内存的镜像。也就是说MEMORY这个中间层,上面接着生产环境层RUNTIME,下面接着持久化层DISK和CONFIG FILE。MEMORY层是我们修改proxysql的唯一正常入口。一般来说在修改一个配置时,首先修改Memory层,确认无误后再接入RUNTIME层,最后持久化到DISK和CONFIG FILE层。也就是说memeory层里面的配置随便改,不影响生产,也不影响磁盘中保存的数据。通过admin接口可以修改mysql_servers、mysql_users、mysql_query_rules、global_variables等表的数据。
[1]: LOAD MYSQL USERS TO RUNTIME / LOAD MYSQL USERS FROM MEMORY #常用。将修改后的配置(在memory层)用到实际生产 [2]: SAVE MYSQL USERS TO MEMORY / SAVE MYSQL USERS FROM RUNTIME #将生产配置拉一份到memory中 [3]: LOAD MYSQL USERS TO MEMORY / LOAD MYSQL USERS FROM DISK #将磁盘中持久化的配置拉一份到memory中来 [4]: SAVE MYSQL USERS TO DISK / SAVE MYSQL USERS FROM MEMORY #常用。将memoery中的配置保存到磁盘中去 [5]: LOAD MYSQL USERS FROM CONFIG #将配置文件中的配置加载到memeory中
[1]: LOAD MYSQL SERVERS TO RUNTIME #常用,让修改的配置生效 [2]: SAVE MYSQL SERVERS TO MEMORY [3]: LOAD MYSQL SERVERS TO MEMORY [4]: SAVE MYSQL SERVERS TO DISK #常用,将修改的配置持久化 [5]: LOAD MYSQL SERVERS FROM CONFIG
[1]: load mysql query rules to run #常用 [2]: save mysql query rules to mem [3]: load mysql query rules to mem [4]: save mysql query rules to disk #常用 [5]: load mysql query rules from config
以下命令加载或保存 mysql variables (global_variables):
1 2 3 4 5
[1]: load mysql variables to runtime [2]: save mysql variables to memory [3]: load mysql variables to memory [4]: save mysql variables to disk [5]: load mysql variables from config
以下命令加载或保存admin variables (select * from global_variables where variable_name like ‘admin-%’):
1 2 3 4 5
[1]: load admin variables to runtime [2]: save admin variables to memory [3]: load admin variables to memory [4]: save admin variables to disk [5]: load admin variables from config
[sun@bogon conf]$ sudo mkdir passwd [sun@bogon conf]$ sudo htpasswd -c passwd/passwd sun New password: Re-type new password: Adding password for user sun [sun@bogon conf]$ cat passwd/passwd sun:$apr1$J5Sg0fQD$KDM3Oypj8Wf9477PHDIzA0
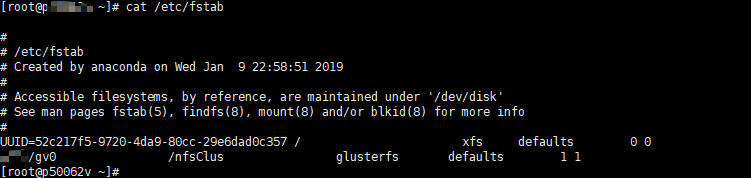
root@wyl01:/gsclient# gluster volume rebalance gv1 start volume rebalance: gv1: success: Rebalance on gv1 has been started successfully. Use rebalance status command to check status of the rebalance process. ID: 76b07497-b26d-438f-bd6f-7659a9aba251 root@wyl01:/gsclient# gluster volume rebalance gv1 status Node Rebalanced-files size scanned failures skipped status run time in h:m:s
root@wyl01:/gsclient# gluster volume remove-brick gv1 gluster004-hf-aiui:/data start Running remove-brick with cluster.force-migration enabled can result in data corruption. It is safer to disable this option so that files that receive writes during migration are not migrated. Files that are not migrated can then be manually copied after the remove-brick commit operation. Do you want to continue with your current cluster.force-migration settings? (y/n) y volume remove-brick start: success ID: e30a9e72-53ef-4e79-a394-38dcac9061ba
#查看移除节点的状态 root@wyl01:/gsclient# gluster volume remove-brick gv1 gluster004-hf-aiui:/data status Node Rebalanced-files size scanned failures skipped status run time in h:m:s
------
192.168.52.125 17 0Bytes 17 0 0 completed 0:00:00
# 移除前先将数据同步到其他brick上 root@wyl01:/gsclient# gluster volume remove-brick gv1 gluster004-hf-aiui:/data commit volume remove-brick commit: success Check the removed bricks to ensure all files are migrated. If files with data are found on the brick path, copy them via a gluster mount point before re-purposing the removed brick.
root@wyl01:/gsclient# gluster volume rebalance gv1 start volume rebalance: gv1: success: Rebalance on gv1 has been started successfully. Use rebalance status command to check status of the rebalance process. ID: 90df529c-d950-4010-9248-19ffa7c83853
root@wyl01:/gsclient# gluster volume remove-brick gv1 replica 2 wyl03-hf-aiui:/data wyl04-hf-aiui:/data start Replica 2 volumes are prone to split-brain. Use Arbiter or Replica 3 to avaoid this. See: http://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/. Do you still want to continue? (y/n) y Running remove-brick with cluster.force-migration enabled can result in data corruption. It is safer to disable this option so that files that receive writes during migration are not migrated. Files that are not migrated can then be manually copied after the remove-brick commit operation. Do you want to continue with your current cluster.force-migration settings? (y/n) y volume remove-brick start: success ID: d4ce7df1-30c9-4124-9986-c9634986609f
# 移除前先将数据同步到其他brick上 root@wyl01:/gsclient# gluster volume remove-brick gv1 replica 2 wyl03-hf-aiui:/data wyl04-hf-aiui:/data commit Replica 2 volumes are prone to split-brain. Use Arbiter or Replica 3 to avaoid this. See: http://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/. Do you still want to continue? (y/n) y volume remove-brick commit: success Check the removed bricks to ensure all files are migrated. If files with data are found on the brick path, copy them via a gluster mount point before re-purposing the removed
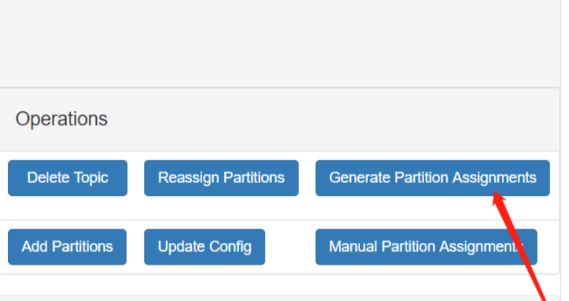
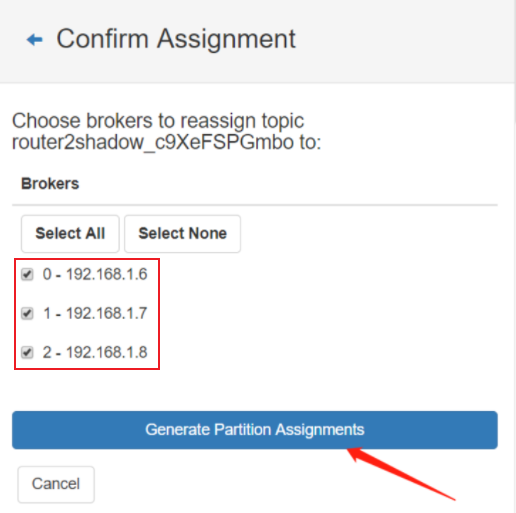
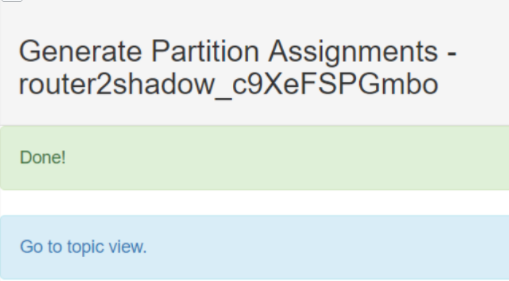
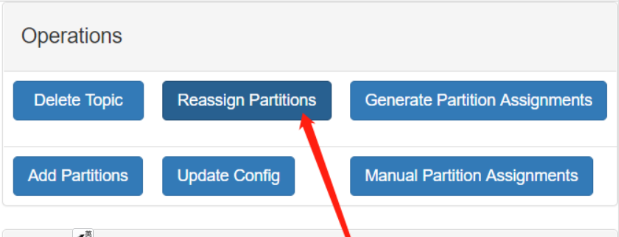
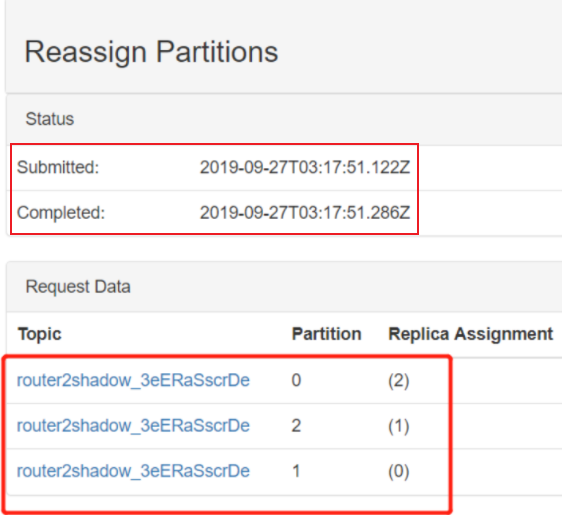
Save this to use as the --reassignment-json-file option during rollback Successfully started partition reassignments for test-3-0,test-3-1,test-3-2,test-3-3,test-4-0,test-4-1,test-4-2,test-4-3
这样就提交了重分配的任务,可以使用下面的命令查看任务的执行状态:
1 2 3 4 5 6 7 8 9 10 11 12 13
➜ bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file expand-cluster-reassignment.json --verify Status of partition reassignment: Reassignment of partition test-3-0 is complete. Reassignment of partition test-3-1 is complete. Reassignment of partition test-3-2 is complete. Reassignment of partition test-3-3 is complete. Reassignment of partition test-4-0 is complete. Reassignment of partition test-4-1 is complete. Reassignment of partition test-4-2 is complete. Reassignment of partition test-4-3 is complete.
Clearing broker-level throttles on brokers 181,182,183,184 Clearing topic-level throttles on topics test-3,test-4
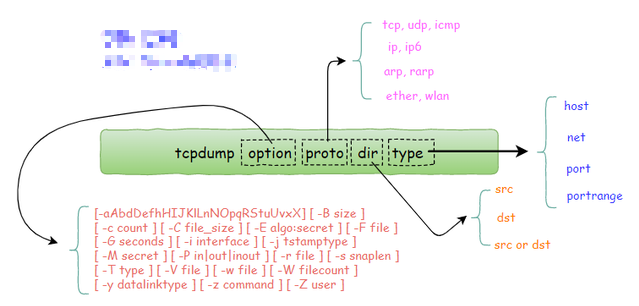
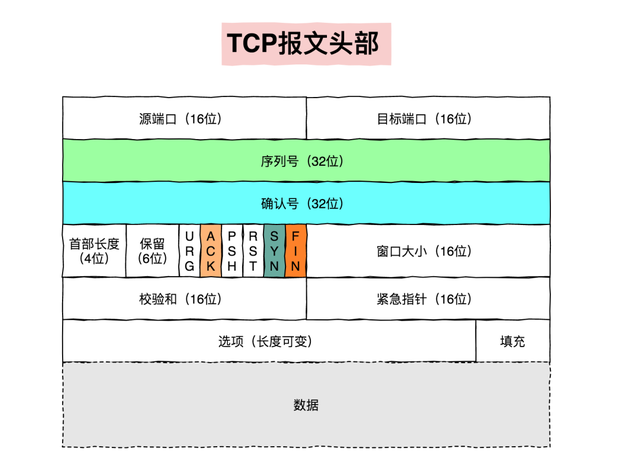
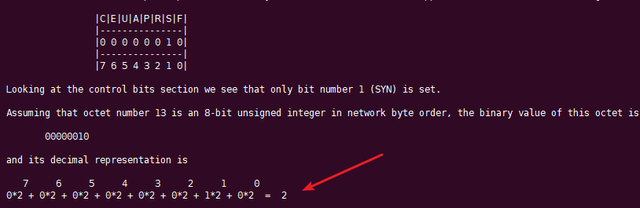
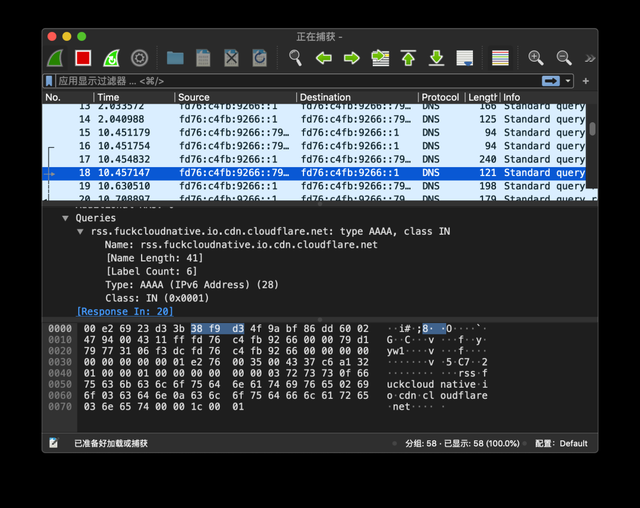
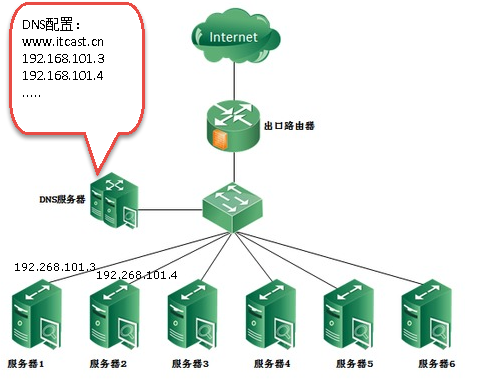
DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的IP地址的过程叫做域名解析(或主机名解析)。DNS协议运行在UDP协议之上,使用端口号53。
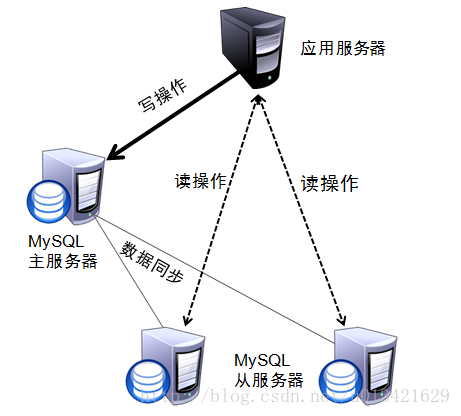
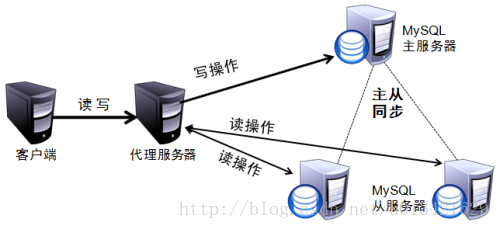
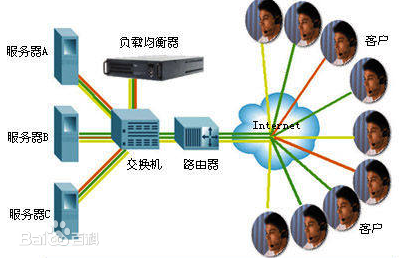
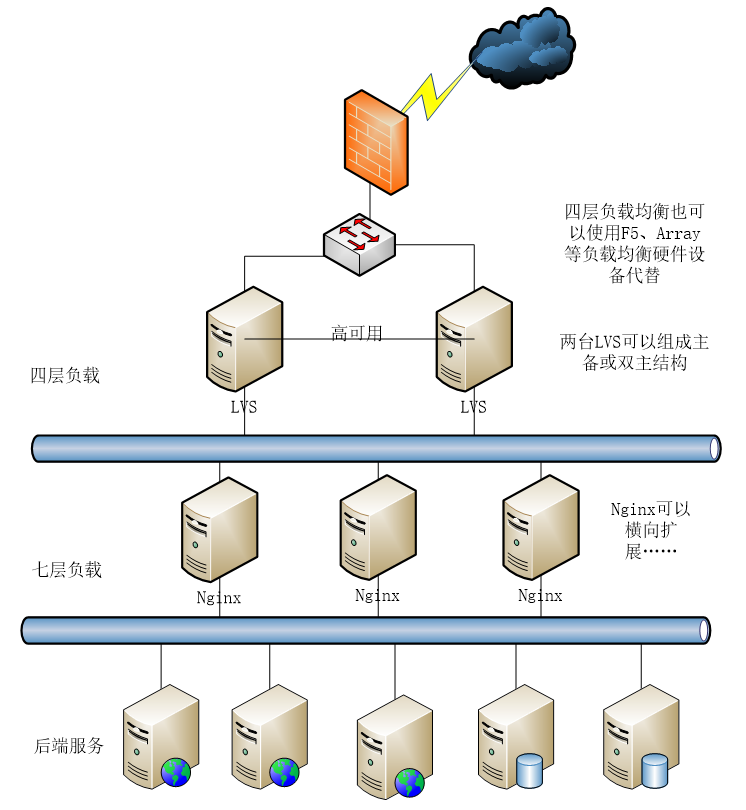
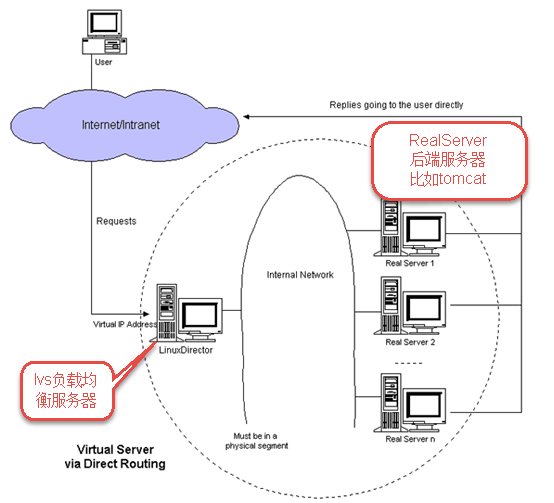
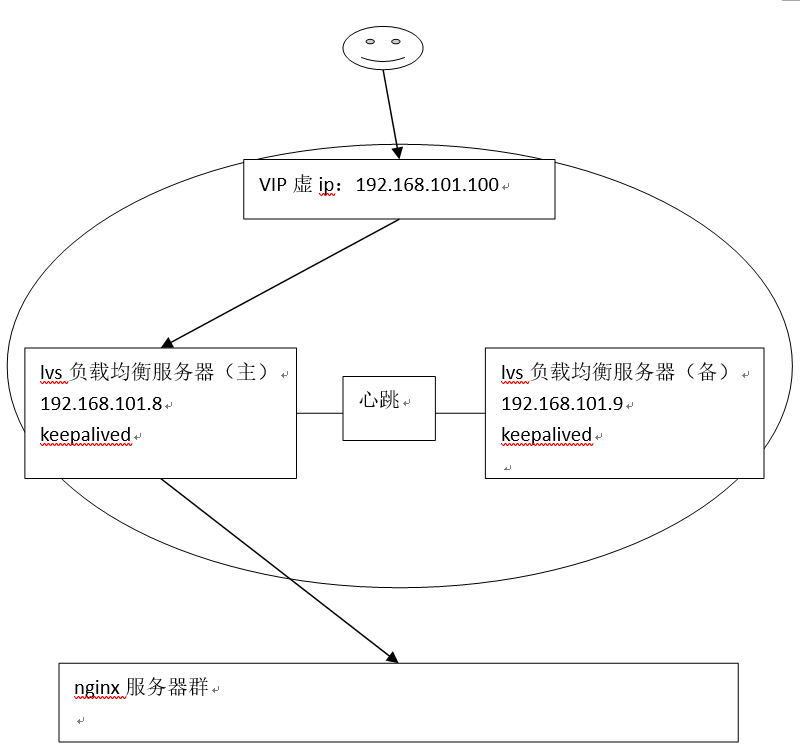
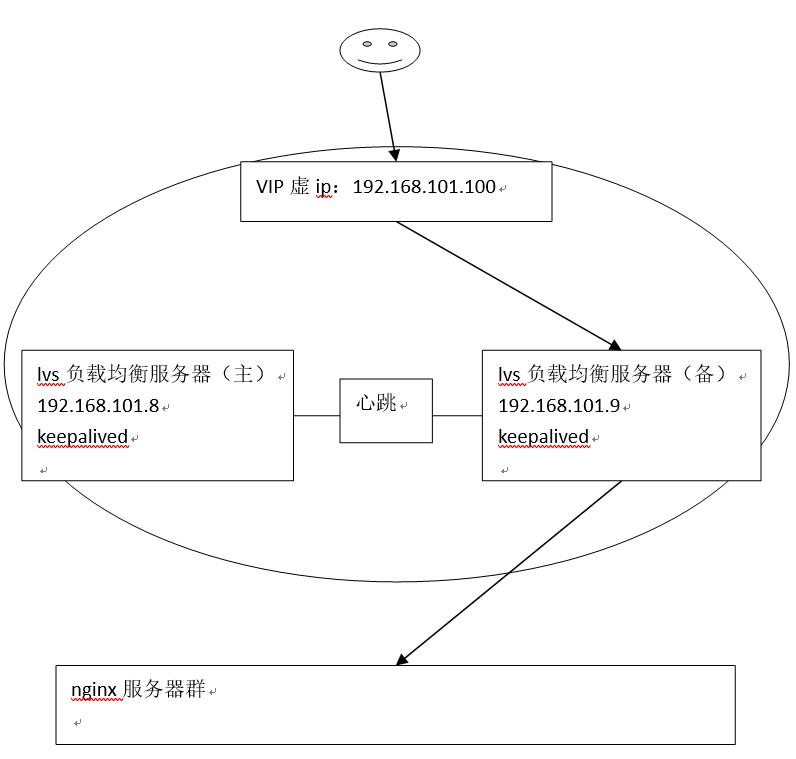
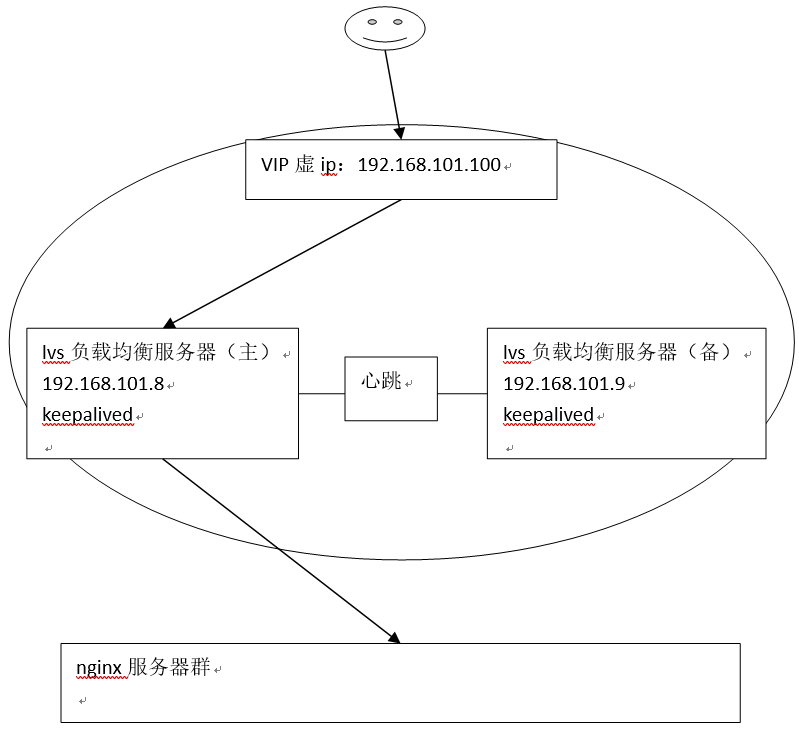
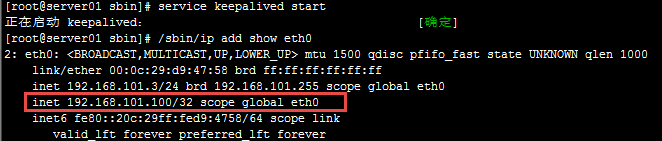
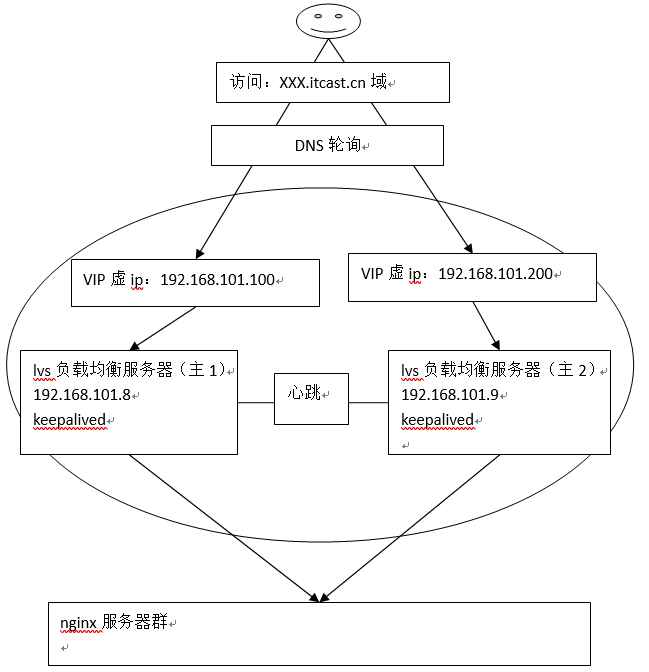
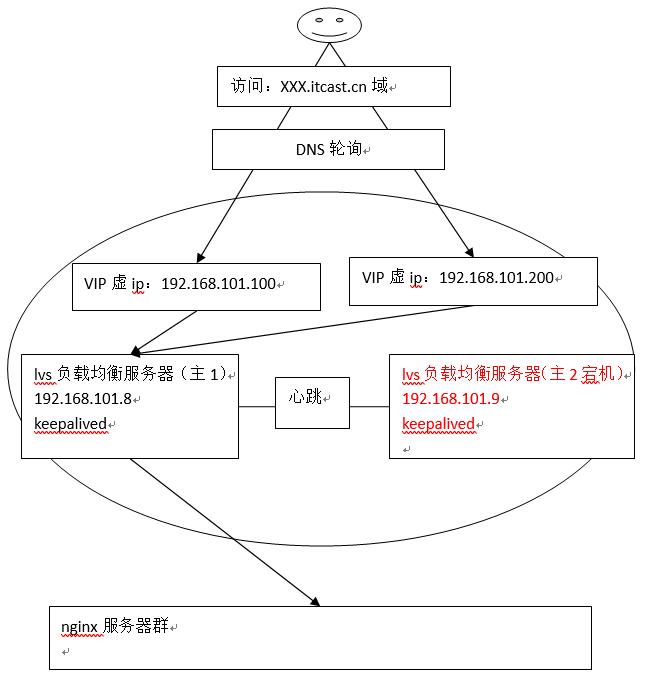
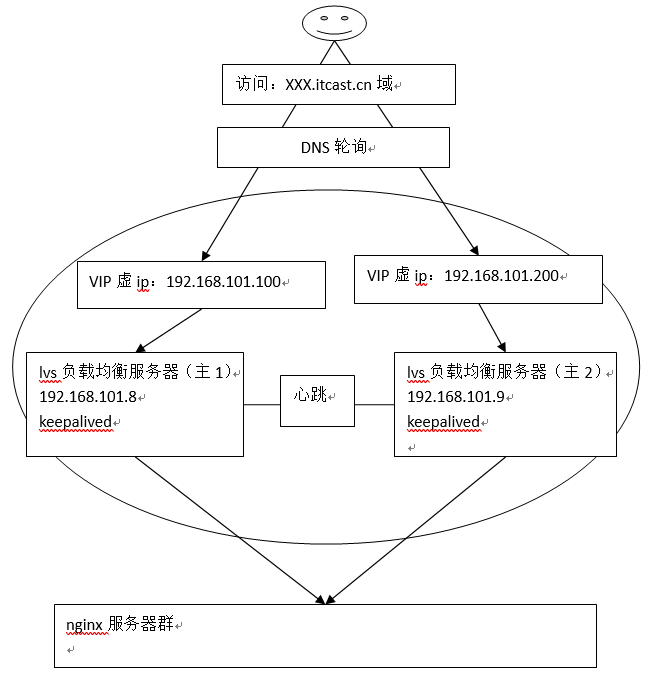
为了屏蔽负载均衡服务器的宕机,需要建立一个备份机。主服务器和备份机上都运行高可用(High Availability)监控程序,通过传送诸如“I am alive”这样的信息来监控对方的运行状况。当备份机不能在一定的时间内收到这样的信息时,它就接管主服务器的服务IP并继续提供负载均衡服务;当备份管理器又从主管理器收到“I am alive”这样的信息时,它就释放服务IP地址,这样的主服务器就开始再次提供负载均衡服务。
cd /opt yum -y install wget wget https://github.com/jumpserver/installer/releases/download/v2.8.2/jumpserver-installer-v2.8.2.tar.gz tar -xf jumpserver-installer-v2.8.2.tar.gz cd jumpserver-installer-v2.8.2
>>> 加载 Docker 镜像 Docker: Pulling from jumpserver/core:v2.8.2 [ OK ] Docker: Pulling from jumpserver/koko:v2.8.2 [ OK ] Docker: Pulling from jumpserver/luna:v2.8.2 [ OK ] Docker: Pulling from jumpserver/nginx:alpine2 [ OK ] Docker: Pulling from jumpserver/redis:6-alpine [ OK ] Docker: Pulling from jumpserver/lina:v2.8.2 [ OK ] Docker: Pulling from jumpserver/mysql:5 [ OK ] Docker: Pulling from jumpserver/guacamole:v2.8.2 [ OK ]