很多朋友不清楚linux如何禁止普通用户su到root,这里需要修改两个配置文件,具体详细配置大家通过本文了解下吧
Linux文件系统卸载小技巧解决大问题
现在系统功能越来越丰富,那么响应的开发资源需要的越来越多,文件存储也越来越必要。无论是你用nfs、glusterfs等等,都需要在linux服务器中设置挂载点并执行挂载后才可使用,但如果fs文件系统有调整,那么可能就需要卸载umount,重新挂载,但是你真的可以顺顺利利的卸载吗?不见得,因为可能有应用在占用该磁盘或者系统在fstab中写入了磁盘自动挂载,本文就详细给你介绍个小技巧,帮你解决该烦恼。

详解TcpDump神器
今天要给大家介绍的一个类Unix下的一个网络数据采集分析工具 – Tcpdump,也就是我们常说的抓包工具。与它功能类似的工具有 wireshark。不同的是wireshark有图形化界面,而tcpdump 则只有命令行。
作为一个运维,经常和服务器打交道,但服务器追求性能很少安装图形界面,因此直接跳过wireshark,直接给大家介绍这个tcpdump神器。
这篇文章借助于很多帮助文档,终于把tcpdump的用法全部研究了个遍。毫不夸张的说,应该可以算是中文里把 tcpdump 讲得最清楚明白,并且最全的文章了。所以本文值得你收藏分享,就怕你错过了,就再也找不到像这样把 tcpdump 讲得直白而且特全的文章了。
生产mysql数据库集群优化<二>--proxysql安装及优化
前面文章对数据库中间层进行了选型,那么要怎么安装,怎么验证,怎么优化,又有哪些坑可以避免呢?本文就详细介绍下。
生产mysql数据库集群优化<一>--选型proxysql
现在微服务几乎成为所有公司的标配,那么业务项目和数据存储的松耦合就成为基本配置,而mysql数据库在互联网公司中应用很广,几乎所有的项目都会有连它的需求。但是如果业务请求量很大,那么最先想到也是最常用的是数据库的读写分离。通常是由dba把数据库分为读写库,对数据进行更新,写入时连接读写库。查询数据时,连接读库。这样可以大大减轻写库的压力。
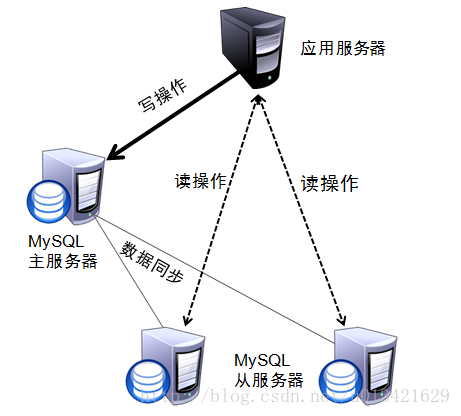
但是这样是由业务根据需求来区分连哪个数据库,但有些开发说我想只配置一个数据库,运维你根据请求类型来区分定义是连接只读库还是读写库。而且业务对时效性也不是很严格。那要怎么做呢?如下图:
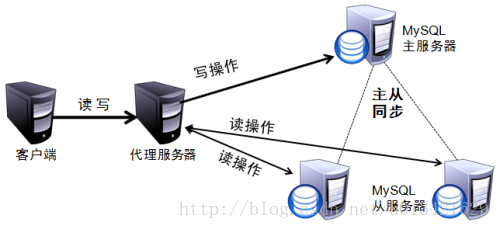
我们就需要增加数据库的代理层,由代理层根据定义的规则来自动区分是连接读写库还是只读库。本文就是聊聊数据库的代理层–ProxySQL。
nginx配置用户名密码来控制访问请求
今天接了个需求:要把一些资源文件从外网提供给客户下载。处于安全和简单快捷考虑,分享一个快速实现并安全性很强的方案:nginx配置账号密码来控制,并且密码还是加密的,再增加白名单配置。此方案简单快捷和安全。
nginx之location匹配优先级及顺序
nginx的使用范围和影响越来越广,很多大厂都在使用,但有些工作多年的同学可能都搞不清楚nginx中location的匹配优先级和匹配顺序是怎样的。今天又有同事不清楚,写配置时总是达不到业务需求,问到我这边帮他搞定了。那么本文就给大家详细聊聊这个问题。
glusterfs集群横向扩容缩容
glusterfs集群的搭建和使用这里就不再赘述了,可以看以前的教程文档。本文主要聊的是随着服务使用量的增加,那么存储集群势必要扩充空间。服务器迁移,需要先扩容后缩容等等。所以本文的主旨是聊glusterfs集群的横向优化:扩容和缩容。
kafka之扩容和缩容
本文讨论Kafka的扩缩容以及故障后如何“补齐”分区。实质上先扩容再缩容也是迁移的操作。
lvs负载均衡实战
通过本文掌握什么是负载均衡及负载均衡的作用和意义;了解lvs负载均衡的三种模式;了解lvs-DR负载均衡部署方法;掌握nginx实现负载均衡的方法;掌握lvs+nginx负载均衡拓扑结构。