前面文章对数据库中间层进行了选型,那么要怎么安装,怎么验证,怎么优化,又有哪些坑可以避免呢?本文就详细介绍下。
ProxySQL 安装 (两种方式)
1 | 1) 采用yum方式安装 |
ProxySQL配置
ProxySQL有配置文件/etc/proxysql.cnf和配置数据库文件/var/lib/proxysql/proxysql.db。这里需要特别注意:如果存在如果存在”proxysql.db”文件(在/var/lib/proxysql目录下),则ProxySQL服务只有在第一次启动时才会去读取proxysql.cnf文件并解析;后面启动会就不会读取proxysql.cnf文件了!如果想要让proxysql.cnf文件里的配置在重启proxysql服务后生效(即想要让proxysql重启时读取并解析proxysql.cnf配置文件),则需要先删除/var/lib/proxysql/proxysql.db数据库文件,然后再重启proxysql服务。这样就相当于初始化启动proxysql服务了,会再次生产一个纯净的proxysql.db数据库文件(如果之前配置了proxysql相关路由规则等,则就会被抹掉)。 官方推荐用admin interface方式!(即在proxysql本机使用mysql客户端连接管理端口)
1 | [root@mysql-proxy ~]# egrep -v "^#|^$" /etc/proxysql.cnf |
proxysql的6032端口是管理入口,账号密码是admin(可以动态修改),允许客户端连接;6033端口就是客户端入口,账号密码通过管理接口去设置。在proxysql本机使用mysql客户端连接到ProxySQL的管理接口(admin interface), 该接口的默认管理员用户和密码都是admin。
mysql_ifaces
也就是说proxysql有一个admin接口专门来做配置,相当于一个mysql shell可以通过sql来让配置实时生效。
mysql_ifaces配置了允许连接proxysql的ip和port
1 | [root@mysql-proxy ~]# vim /etc/proxysql.cnf |
如果ip配置为0.0.0.0表示不限制ip,但是出于安全考虑,admin用户无论怎么设置都只能在本机登录!!!
admin_credentials
这个key保存所有可以操作proxysql的用户名和密码,格式为:user:pass;user1:pass1,这里可以修改密码或定义一个非admin的用户用于远程登录。 前提是保证想要管理proxysql的机器安装有mysql client客户端!
1 | 先在proxysql本机登录 (因为初始账号密码是admin:admin,只能在本机登录), 这里的proxysql本机地址是172.16.60.214 |
ProxySQL的库、表说明 (默认管理端口是6032,客户端服务端口是6033。默认的用户名密码都是 admin)
1 | 通过管理端口6032去连接的 (注意, 下面连接命令中后面的--prompt 'admin'字段可以不加,也是可以登录进去的) |
global_variables 有80多个变量可以设置,其中就包括监听的端口、管理账号、禁用monitor等
1 | (admin@127.0.0.1:6032) [(none)]> show tables; |
- hostgroup_id: ProxySQL通过 hostgroup (下称HG) 的形式组织后端db实例。一个 HG 代表同属于一个角色
- 该表的主键是 (hostgroup_id, hostname, port),可以看到一个 hostname:port 可以在多个hostgroup里面,如上面的 10.0.100.100:3307,这样可以避免 HG 1000 的从库全都不可用时,依然可以把读请求发到主库上。
- 一个 HG 可以有多个实例,即多个从库,可以通过 weight 分配权重
- hostgroup_id 0 是一个特殊的HG,路由查询的时候,没有匹配到规则则默认选择 HG 0
- status:
- ONLINE: 当前后端实例状态正常
- SHUNNED: 临时被剔除,可能因为后端 too many connections error,或者超过了可容忍延迟阀值 max_replication_lag
- OFFLINE_SOFT: “软离线”状态,不再接受新的连接,但已建立的连接会等待活跃事务完成。
- OFFLINE_HARD: “硬离线”状态,不再接受新的连接,已建立的连接或被强制中断。当后端实例宕机或网络不可达,会出现。
- max_connections: 允许连接到该后端mysql实例的最大连接数。不要大于MySQL设置的 max_connections,如果后端实例 hostname:port 在多个 hostgroup 里,以较大者为准,而不是各自独立允许的最大连接数。
- max_replication_lag: 允许的最大延迟,主库不受这个影响,默认0。如果 > 0, monitor 模块监控主从延迟大于阀值时,会临时把它变为 SHUNNED 。
- max_latency_ms: mysql_ping 响应时间,大于这个阀值会把它从连接池剔除(即使是ONLINE)
- comment: 备注,不建议留空。可以通过它的内容如json格式的数据,配合自己写的check脚本,完成一些自动化的工作。
表 mysql_users
1 | MySQL [(none)]> show create table mysql_users\G; |
- username, password: 连接后端db的用户密码。
这个密码你可以插入明文,也可以插入hash加密后的密文,proxysql会检查你插入的时候密码是否以 * 开头来判断,而且密文要在其它地方使用 PASSWORD()生成。但到 runtime_mysql_users 里,都统一变成了密文,所以可以明文插入,再 SAVE MYSQL USERS TO MEM,此时看到的也是HASH密文。
- active: 是否生效该用户。
- default_hostgroup: 这个用户的请求没有匹配到规则时,默认发到这个 hostgroup,默认0
- default_schema: 这个用户连接时没有指定 database name 时,默认使用的schema
注意表面上看默认为NULL,但实际上受到变量 mysql-default_schema 的影响,默认为 information_schema。关于这个参考我所提的 issue #988
- transaction_persistent: 如果设置为1,连接上ProxySQL的会话后,如果在一个hostgroup上开启了事务,那么后续的sql都继续维持在这个hostgroup上,不伦是否会匹配上其它路由规则,直到事务结束。
虽然默认是0,但我建议还是设成1,虽然一般来说由于前段应用的空值,为0出问题的情况几乎很小。作者也在考虑默认设成 1,refer this issue #793
- frontend, backend: 目前版本这两个都需要使用默认的1,将来有可能会把 Client -> ProxySQL (frontend) 与 ProxySQL -> BackendDB (backend)的认证分开。从 runtime_mysql_users 表内容看到,记录数比 mysql_users 多了一倍,就是把前端认证与后端认证独立出来的结果。
- fast_forward: 忽略查询重写/缓存层,直接把这个用户的请求透传到后端DB。相当于只用它的连接池功能,一般不用,路由规则 .* 就行了。
表 mysql_replication_hostgroups
1 | MySQL [(none)]> show create table mysql_replication_hostgroups\G; |
定义 hostgroup 的主从关系。ProxySQL monitor 模块会监控 HG 后端所有servers 的 read_only 变量,如果发现从库的 read_only 变为0、主库变为1,则认为角色互换了,自动改写 mysql_servers 表里面 hostgroup 关系,达到自动 Failover 效果。
表 mysql_query_rules
mysql_query_rules 是ProxySQL非常核心一个表,定义查询路由规则
1 | MySQL [(none)]> show create table mysql_query_rules\G; |
- rule_id: 表主键,自增。规则处理是以 rule_id 的顺序进行。
- active: 只有 active=1 的规则才会参与匹配。
- username: 如果非 NULL,只有连接用户是 username 的值才会匹配。
- schemaname: 如果非 NULL,只有查询连接使用的db是 schemaname 的值才会匹配。
注意如果是 NULL,不代表连接没有使用schema,而是不伦任何schema都进一步匹配。
- flagIN, flagOUT, apply: 用来定义路由链 chains of rules。
- 首先会检查 flagIN=0 的规则,以rule_id的顺序;如果都没匹配上,则走这个用户的 default_hostgroup。
- 当匹配一条规则后,会检查 flagOUT。
- 如果不为NULL,并且 flagIN != flagOUT ,则进入以flagIN为上一个flagOUT值的新规则链。
- 如果不为NULL,并且 flagIN = flagOUT,则应用这条规则。
- 如果为NULL,或者 apply=1,则结束,应用这条规则。
- 如果最终没有匹配到,则找到这个用户的 default_hostgroup。
- client_addr: 匹配客户端来源IP
- proxy_addr, proxy_port: 匹配本地proxysql的IP、端口。我目前没有想到它的应用场景,可能是把proxysql监听在多个接口上,分发到不同的业务?
- digest: 精确的匹配一类查询。
- match_digest: 正则匹配一类查询。query digest 是指对查询去掉具体值后进行“模糊化”后的查询,类似 pt-fingerprint / pt-query-digest 的效果。
- match_pattern: 正则匹配查询。
以上都是匹配查询的规则,1.3.5版本使用的正则引擎只有 RE2 ,1.4版本可以通过变量 mysql-query_processor_regex 设置 RE2 或者 PCRE,且1.4开始默认是PCRE。
推荐用 match_digest 。关于每条查询都会计算digest对性能的影响,计算query digest确实会有性能损失,但是这却是proxysql里面非常重要的特性,主要是两点:
- proxysql无法知道连接复用(multipexing)是否必须被自动禁用,比如连接里面有variables/tmp tables/lock table等特殊命令,是不能复用的。
- 完整的查询去匹配正则的效率,一般没有参数化后的查询匹配效率高,因为有很长的字符串内容需要处理。再者,SELECT * FROM randomtable WHERE comment LIKE ‘%INTO sbtest1 % FROM sbtest2 %’字符串里有类似这样的语句,很难排除误匹配。
- negate_match_pattern: 反向匹配,相当于对 match_digest/match_pattern 的匹配取反。
- re_modifiers: 修改正则匹配的参数,比如默认的:忽略大小写CASELESS、禁用GLOBAL.
上面都是匹配规则,下面是匹配后的行为
- replace_pattern: 查询重写,默认为空,不rewrite。
- rewrite规则要遵守 RE2::Replace 。
destination_hostgroup: 路由查询到这个 hostgroup。当然如果用户显式 start transaction 且 transaction_persistent=1,那么即使匹配到了,也依然按照事务里第一条sql的路由规则去走。
- cache_ttl: 查询结果缓存的毫秒数。
proxysql这个 Query Cache 与 MySQL 自带的query cache不是同一个。proxysql query cache也不会关心后端数据是否被修改,它所做的就是针对某些特定种类的查询结果进行缓存,比如一些历史数据的count结果。一般不设。
- timeout: 这一类查询执行的最大时间(毫秒),超时则自动kill。
这是对后端DB的保护机制,相当于阿里云RDS loose_max_statement_time 变量的功能,但是注意不同的是,阿里云这个变量的时间时不包括DML操作出现InnoDB行锁等待的时间,而ProxySQL的这个 timeout 是计算从发送sql到等待响应的时间。默认mysql-default_query_timeout给的是 10h .
- retries: 语句在执行时失败时,重试次数。默认由 mysql-query_retries_on_failure变量指定,为1 。
个人建议把它设成0,即不重试。因为执行失败,对select而言很少见,主要是dml,但自己重试对数据不放心。
- delay: 查询延迟执行,这是ProxySQL提供的限流机制,会让其它的查询优先执行。
默认值 mysql-default_query_delay,为0。我们一般不用,其实还是要配合应用端使用,比如这边延迟执行,但上层等待你返回,那前端不就堵住了,没准出现雪崩效应。
- mirror_flagOUT,mirror_hostgroup
这两个高级了,目前这部分文档不全,功能是SQL镜像。顾名思义,就是把匹配到的SQL除了发送到 destination_hostgroup,同时镜像一份到这里的hostgroup,比如我们的测试库。比如这种场景,数据库要从5.6升级到5.7,要验证现有查询语句对5.7的适用情况,就可以把生产流量镜像到5.7新库上验证。
- error_msg: 默认为NULL,如果指定了则这个查询直接被 block 掉,马上返回这个错误信息。
这个功能也很实用,比如线上突然冒出一个 “坏查询”,应用端不方便马上发版解决,我们就可以在这配置一个规则,把查询屏蔽掉,想正常的mysql报错那样抛异常。下一篇文章有演示。
- multiplex: 连接是否复用。
- log: 是否记录查询日志。可以看到log是否记录的对象是根据规则。
要开启日志记录,需要设置变量 mysql-eventslog_filename 来指定文件名,然后这个 log 标记为1。但是目前proxysql记录的日志是二进制格式,需要特定的工具才能读取: eventslog_reader_sample 。这个工具在源码目录 tools下面。
proxysql对后端server健康检查
1 | MySQL [monitor]> show variables like "mysql-monitor%"; |
ProxySQL配置后端DB server
两种方式,区别在于
1) 一种是在往mysql_servers表中添加server时就为其划分好hostgroup_id(例如0表示写组,1表示读组)
2) 另一种往mysql_servers表中添加server时不区分hostgroup_id(例如全部设为0),然后通过mysql_replication_hostgroups表中的值,
根据proxysql检测到的各server的read_only变量值来自动为后端server设置hostgroup_id
这里强烈推荐用第一种方式
因为第一种是完全由我们控制的;而第二种假如我们误将读server的read_only属性设置为0,则proxysql会将其重新分配到写组,这绝对是不期望的。
ProxySQL下添加与修改配置
1 | 1) 添加配置 |
实战功能验证
针对GTID模式的主从同步,另两个从库都要设置read_only=on
接下来通过实战操作来全面了解一下 ProxySQL 的特性和使用场景。
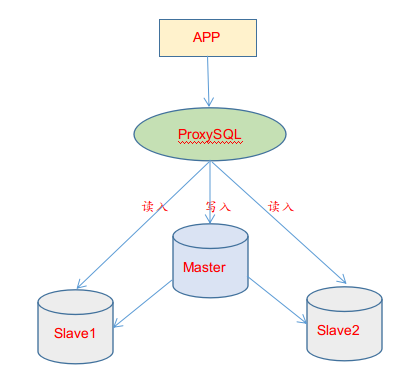
实验环境
1 | 172.16.60.211 mysql-master 安装Mysql5.7 |
安装Mysql 5.7 (在三个mysql节点上安装)
1 | 在三个mysql节点机上使用yum方式安装Mysql5.7,参考:https://www.cnblogs.com/kevingrace/p/8340690.html |
*配置Mysql基于GTID的主从同步 *
在mysql-master 和 mysql-slave1、mysql-slave2节点上
1 | 1) 主数据库mysql-master (172.16.60.211)的配置操作 |
安装配置ProxySQL
已经在上面第一步中介绍了安装方法,这里采用rpm包方式安装,安装过程省略……..
ProxySQL实现读写分离
向ProxySQL中添加MySQL节点
1 | 使用insert语句添加主机到mysql_servers表中,其中:hostgroup_id 为10表示写组,为20表示读组。 |
监控后端MySQL节点
添加Mysql节点之后,还需要监控这些后端节点。对于后端是主从复制的环境来说,这是必须的,因为ProxySQL需要通过每个节点的read_only值来自动调整
它们是属于读组还是写组。
首先在后端master主数据节点上创建一个用于监控的用户名(只需在master上创建即可,因为会复制到slave上),这个用户名只需具有USAGE权限即可。如果还需
要监控复制结构中slave是否严重延迟于master(这个俗语叫做”拖后腿”,术语叫做”replication lag”),则还需具备replication client权限。
1 | 在mysql-master主数据库节点行执行: |
配置mysql_users
上面的所有配置都是关于后端MySQL节点的,现在可以配置关于SQL语句的,包括:发送SQL语句的用户、SQL语句的路由规则、SQL查询的缓存、SQL语句的重写等等。本小节是SQL请求所使用的用户配置,例如root用户。这要求我们需要先在后端MySQL节点添加好相关用户。这里以root和sqlsender两个用户名为例.
1 | 首先,在mysql-master主数据库节点上执行:(只需master执行即可,会复制给两个slave) |
读写分离:配置路由规则
ProxySQL的路由规则非常灵活,可以基于用户、基于schema以及基于每个语句实现路由规则的定制。本案例作为一个入门配置,实现一个最简单的语句级路由规则,从而实现读写分离。
必须注意: 这只是实验,实际的路由规则绝不应该仅根据所谓的读、写操作进行分离,而是从各项指标中找出压力大、执行频繁的语句单独写规则、做缓存等等。和查询规则有关的表有两个:mysql_query_rules和mysql_query_rules_fast_routing,后者是前者的扩展表,1.4.7之后才支持该快速路由表。本案例只介绍第一个表。插入两个规则,目的是将select语句分离到hostgroup_id=20的读组,但由于select语句中有一个特殊语句SELECT…FOR UPDATE它会申请写锁,所以应该路由到hostgroup_id=10的写组.
1 | [root@mysql-proxy ~]# mysql -uadmin -padmin -P6032 -h127.0.0.1 |
测试读写分离效果
1 | 由于读写操作都记录在proxysql的stats_mysql_query_digest表内。 |
负载均衡测试 (加权轮询)
如上已经配置好一主(mysql-master,在hostgroup10写组内)、两从(mysql-slave1和mysql-slave2,在hostgroup20读组内) ,并且已经在”mysql_query_rules”表中配置了路由规则,即写操作转发到hostgroup10组,读操作转发到hostgroup20组.
1 | MySQL [(none)]> select * from mysql_query_rules; |
开启ProxySQL的Web统计功能
1 | 首先打开web功能 |
查看web端口是否正常打开
1 | [root@mysql-proxy ~]# lsof -i:6080 |
访问http://172.16.60.214:6080并使用stats:stats登录即可查看一些统计信息。
scheduler打印proxysql状态到日志
1 | [root@mysql-proxy ~]# mkdir -p /opt/proxysql/log |

