目的
通过本文教程,帮助你搭建glusterfs集群共享存储。
环境说明
3台机器安装 GlusterFS 组成一个集群
服务器
10.6.0.140
10.6.0.192
10.6.0.196
客户端:
10.6.0.94 node-94
安装
CentOS 安装 glusterfs 非常的简单
安装glusterfs
在三个节点都执行
1 | #配置 hosts |
配置 GlusterFS 集群
启动 glusterFS
1 | systemctl start glusterd.service |
在 swarm-manager 节点上配置,将 节点 加入到 集群中。
1 | [root@swarm-manager ~]#gluster peer probe swarm-manager |
查看集群状态
1 | [root@swarm-manager ~]#gluster peer status |
创建数据存储目录
1 | [root@swarm-manager ~]#mkdir -p /opt/gluster/data |
查看volume 状态
1 | [root@swarm-manager ~]#gluster volume info |
创建GlusterFS磁盘:
1 | [root@swarm-manager ~]#gluster volume create models replica 3 swarm-manager:/opt/gluster/data swarm-node-1:/opt/gluster/data swarm-node-2:/opt/gluster/data force |
volume 模式说明
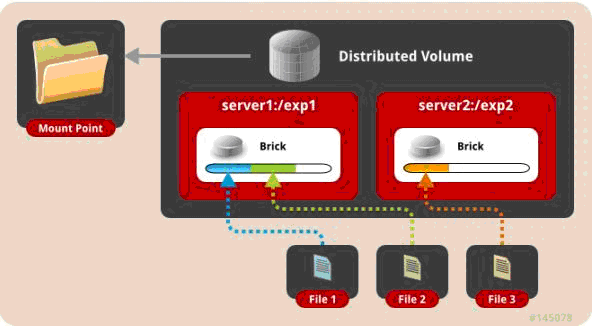
一、 默认模式,既DHT, 也叫 分布卷: 将文件已hash算法随机分布到 一台服务器节点中存储。
1 | gluster volume create test-volume server1:/exp1 server2:/exp2 |
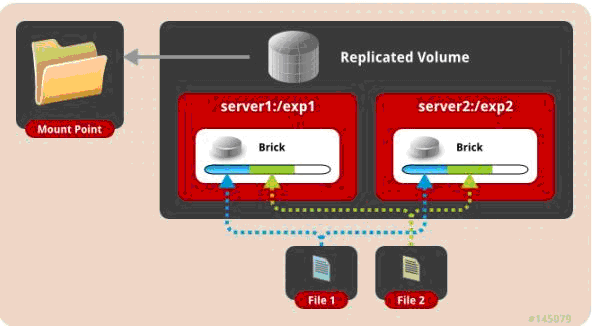
二、 复制模式,既AFR, 创建volume 时带 replica x 数量: 将文件复制到 replica x 个节点中。
1 | gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 |
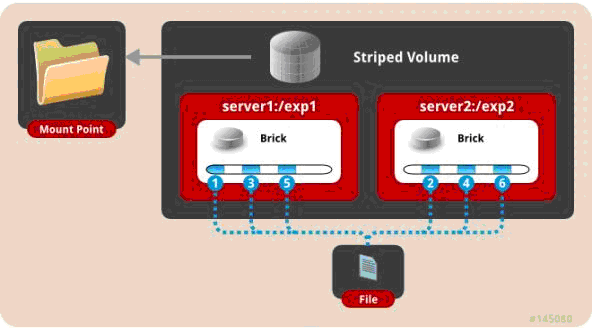
三、 条带模式,既Striped, 创建volume 时带 stripe x 数量: 将文件切割成数据块,分别存储到 stripe x 个节点中 ( 类似raid 0 )。
1 | gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 |
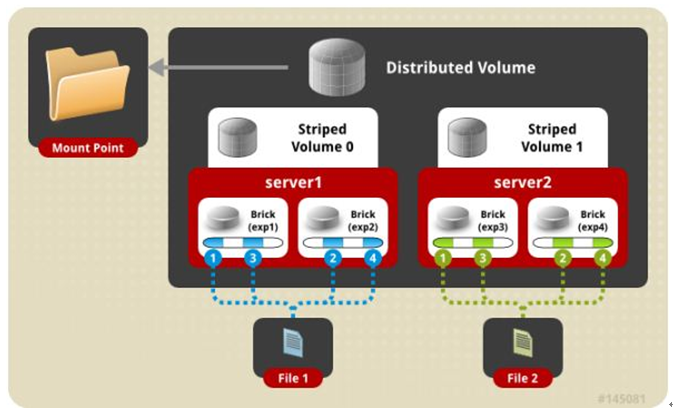
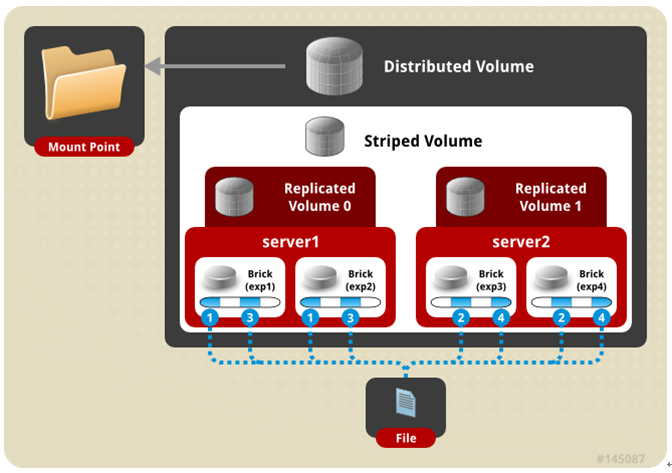
四、 分布式条带模式(组合型),最少需要4台服务器才能创建。 创建volume 时 stripe 2 server = 4 个节点: 是DHT 与 Striped 的组合型。
1 | gluster volume create test-volume stripe 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 |
五、 分布式复制模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 replica 2 server = 4 个节点:是DHT 与 AFR 的组合型。
1 | gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 |
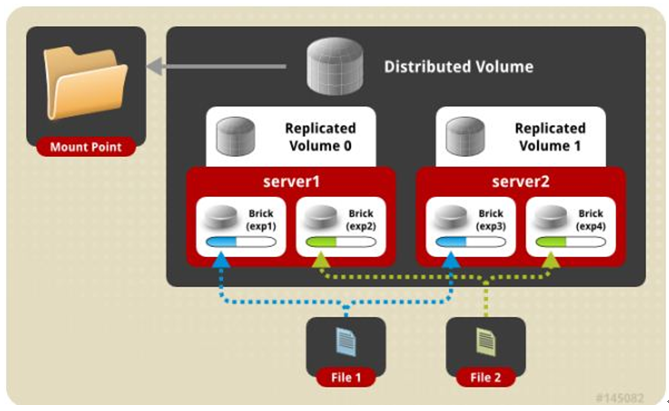
六、 条带复制卷模式(组合型), 最少需要4台服务器才能创建。 创建volume 时 stripe 2 replica 2 server = 4 个节点: 是 Striped 与 AFR 的组合型。
1 | gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 |
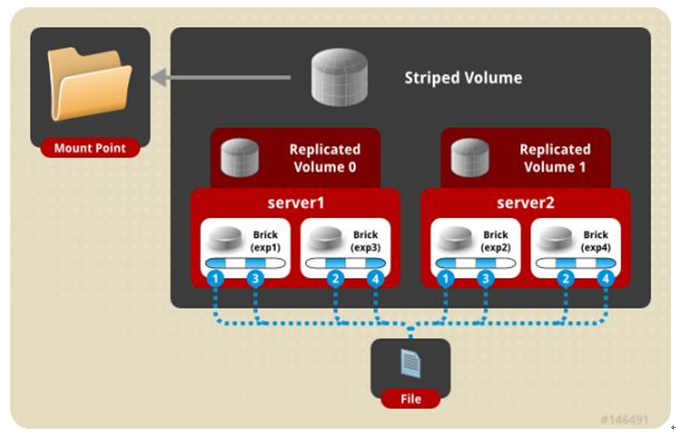
七、 三种模式混合, 至少需要8台 服务器才能创建。 stripe 2 replica 2 , 每4个节点 组成一个 组。
1 | gluster volume create test-volume stripe 2 replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4 server5:/exp5 server6:/exp6 server7:/exp7 server8:/exp8 |
查看 volume 状态
1 | [root@swarm-manager ~]#gluster volume info |
启动 models
1 | [root@swarm-manager ~]#gluster volume start models |
gluster 性能调优
开启 指定 volume 的配额: (models 为 volume 名称)
1 | gluster volume quota models enable |
限制 models 中 / (既总目录) 最大使用 80GB 空间
1 | gluster volume quota models limit-usage / 80GB |
#设置 cache 4GB
1 | gluster volume set models performance.cache-size 4GB |
#开启 异步 , 后台操作
1 | gluster volume set models performance.flush-behind on |
#设置 io 线程 32
1 | gluster volume set models performance.io-thread-count 32 |
#设置 回写 (写数据时间,先写入缓存内,再写入硬盘)
1 | gluster volume set models performance.write-behind on |
部署GlusterFS客户端
mount GlusterFS文件系统 (客户端必须加入 glusterfs hosts 否则报错。)
1 | [root@node-94 ~]#yum install -y glusterfs glusterfs-fuse |
测试
单文件测试
测试方式:客户端创建一个 1G 的文件
DHT模式
1 | time dd if=/dev/zero of=hello bs=1000M count=1 |
AFR 模式
1 | time dd if=/dev/zero of=hello.txt bs=1024M count=1 |
Striped 模式
1 | time dd if=/dev/zero of=hello bs=1000M count=1 |
条带复制卷模式 (Number of Bricks: 1 x 2 x 2 = 4)
1 | [root@node-94 ~]#time dd if=/dev/zero of=hello bs=1000M count=1 |
分布式复制模式 (Number of Bricks: 2 x 2 = 4)
1 | [root@node-94 ~]#time dd if=/dev/zero of=haha bs=100M count=10 |
针对 分布式复制模式还做了如下测试:
4K随机测试
写测试
1 | # 安装fio |
读测试
1 | fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randread -size=10G -filename=1.txt -name="EBS 4KB randread test" -iodepth=8 -runtime=60 |
512K顺序写测试
1 | fio -ioengine=libaio -bs=512k -direct=1 -thread -rw=write -size=10G -filename=512.txt -name="EBS 512KB seqwrite test" -iodepth=64 -runtime=60 |
其他的维护命令:
查看GlusterFS中所有的volume
1 | gluster volume list |
删除GlusterFS磁盘
1 | gluster volume stop models #停止名字为 models 的磁盘 |
注: 删除 磁盘 以后,必须删除 磁盘( /opt/gluster/data ) 中的 ( .glusterfs/ .trashcan/ )目录。
否则创建新 volume 相同的 磁盘 会出现文件 不分布,或者 类型 错乱 的问题。
卸载某个节点GlusterFS磁盘
1 | gluster peer detach swarm-node-2 |
设置访问限制,按照每个volume 来限制
1 | gluster volume set models auth.allow 10.6.0.*,10.7.0. |
添加GlusterFS节点
1 | gluster peer probe swarm-node-3 |
注:如果是复制卷或者条带卷,则每次添加的Brick数必须是replica或者stripe的整数倍
配置卷
1 | gluster volume set |
缩容volume
1 | #先将数据迁移到其它可用的Brick,迁移结束后才将该Brick移除: |
注意,如果是复制卷或者条带卷,则每次移除的Brick数必须是replica或者stripe的整数倍。
扩容
1 | gluster volume add-brick models swarm-node-2:/opt/gluster/data |
修复命令
1 | gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data commit -force |
迁移volume
1 | gluster volume replace-brick models swarm-node-2:/opt/gluster/data swarm-node-3:/opt/gluster/data start |
均衡volume
1 | gluster volume models lay-outstart |

